Stacking Based Ensemble Learning


Algorithm Steps
Step 1: Learn first-level classifiers based on the original training data set.
We have several choices to learn base classifiers.
We can apply Bootstrap sampling technique tolearn independent classifiers;
we can adopt the strategy used in Boosting, i.e.,adaptively learn base classifiers based on data with a weight distribution;
we can tune parameters in a learning algorithm to generate diverse base classifiers (homogeneous classifiers);
we can apply different classification methods and/or sampling methods to generate base classifiers (heterogeneous classifiers).
Step 2: Construct a new data set based on the output of base classifiers.
Here the output predicted labels of the first-level classifiers are regarded as new features, and the original class labels are kept as the labels in the new data set. Instead of using predicted labels we could use probability estimations of first-level classifiers. We could also use different activation functions like Relu, Logistic or Tanh to create new features.
Step 3: Learn a second-level classifier based on the newly constructed data set.
Any learning method could be applied to learn second-level classifier.
The Stacking is a general framework. We can plug in different classifiers and learning approaches to create the first-level features and transform the data into another feature space.
Example
We show the basic procedure of Stacking using the data below. We use 2 first-level classifier. Table 1 shows the points in the data set.


Table 1 shows the training data set and Table 2 shows the new data generated from the Training Data. After applying the two classifiers we can construct a new data set based on the output of base classifiers. Since there are two base classifiers, our new x_new has two dimensions. The first one is the predicted label from the first classifier and the second one is the predicted label from the second classifier. The new dataset is used for the second-level classifier.
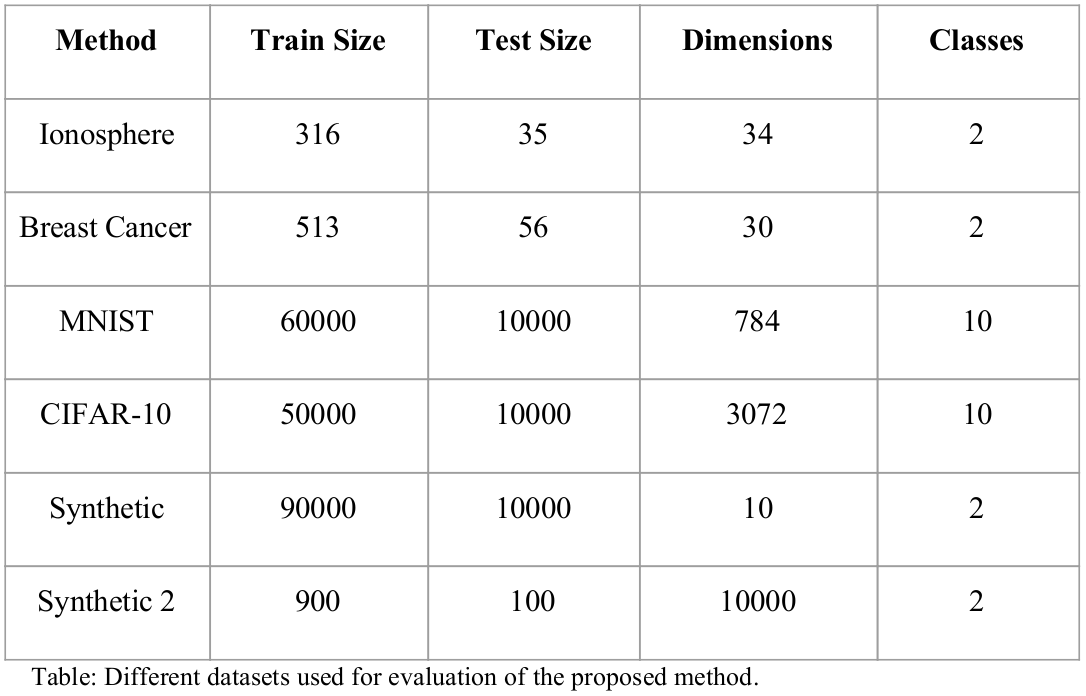
Datasets used for Evaluation
Ionosphere Dataset
Breast Cancer Dataset
MNIST Handwritten Digit Database
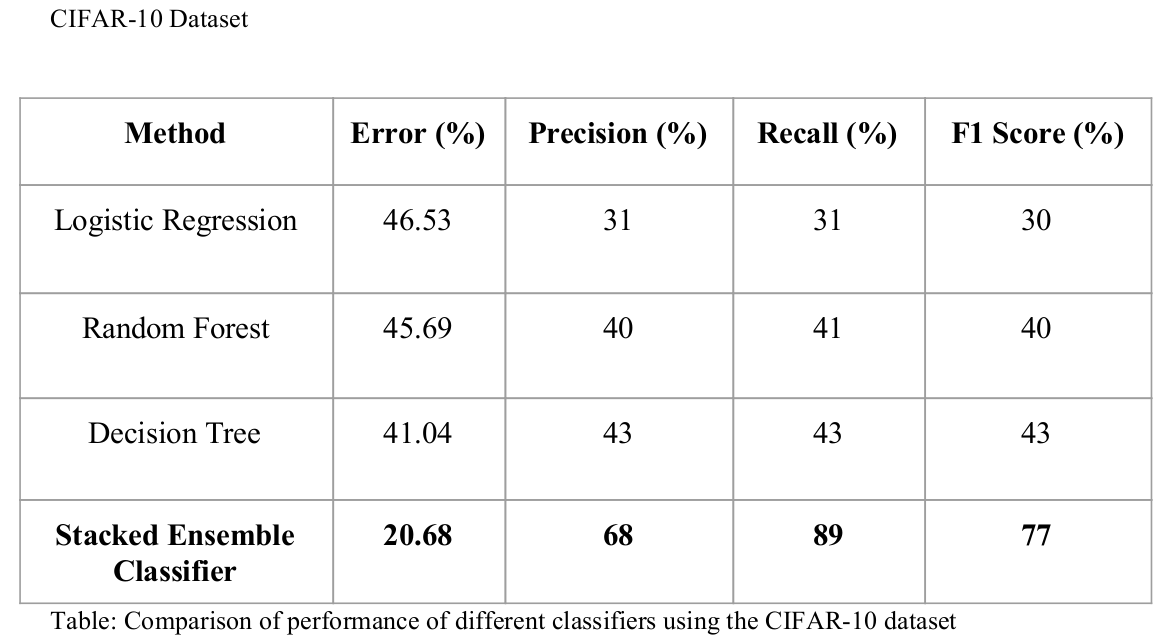
CIFAR-10 Dataset
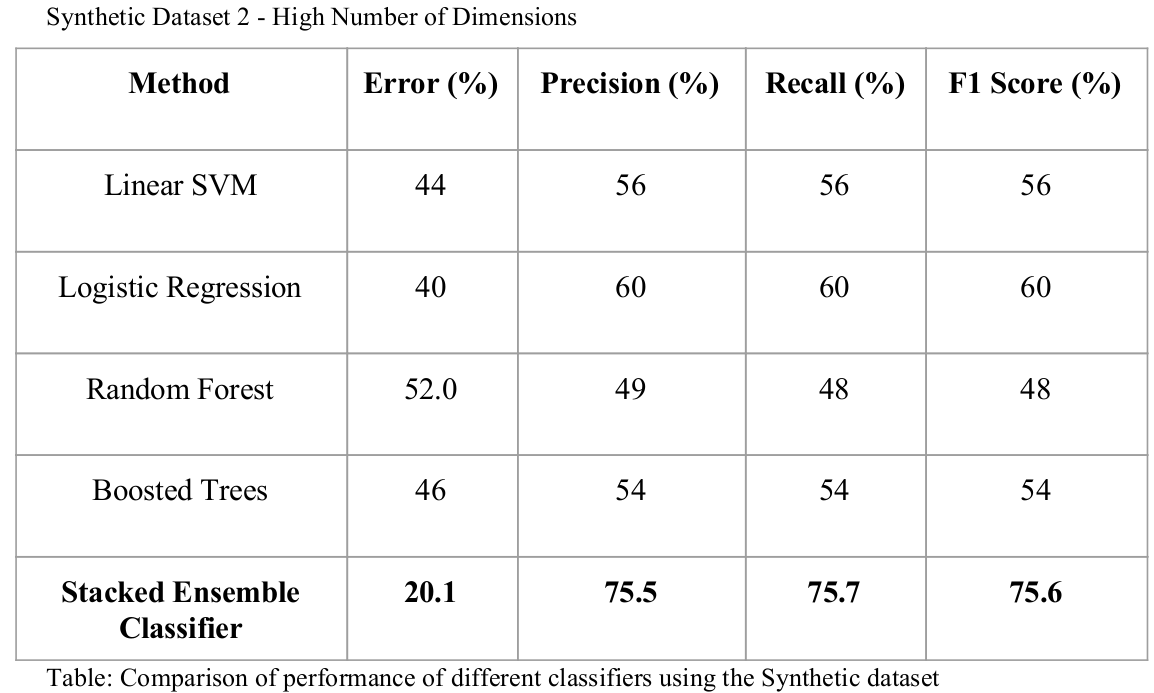
Synthetic Datasets
Experiments






View Source Code (Github)
References
[1] P.Smyth and D.Wolpert. Linearly combining density estimators via stacking . Machine Learning, 36(1-2):59-83, 1999.
[2] Breiman, L. (1996). Bagging predictors. Machine learning, 24(2), 123-140.
[3] Liu, X. Y., Wu, J., & Zhou, Z. H. (2009). Exploratory undersampling for class-imbalance learning. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39(2), 539-550.
[4] Charu C. Aggarwal, Data Classification: Algorithms and Applications, Chapman & Hall/CRC, 2014.
[5] Fernández-Delgado, M., Cernadas, E., Barro, S., & Amorim, D. (2014). Do we need hundreds of classifiers to solve real world classification problems. J. Mach. Learn. Res, 15(1), 3133-3181.