Topic
|
Date
|
Notes
|
Introduction, Bayesian learning, and Python
|
09/04/19
|
Introduction
Background
Unix and login to NJIT machines
|
Bayesian learning
|
09/09/2019
|
Bayesian learning
Bayesian decision theory example problem
Textbook reading: 4.1 to 4.5, 5.1, 5.2, 5.4, 5.5
|
Python
|
09/11/2019
|
Python
More on Python
Python cheat sheet
Python practice problems
Python example 1
Python example 2
Python example 3
|
Nearest means and naive-bayes
|
09/16/2019
|
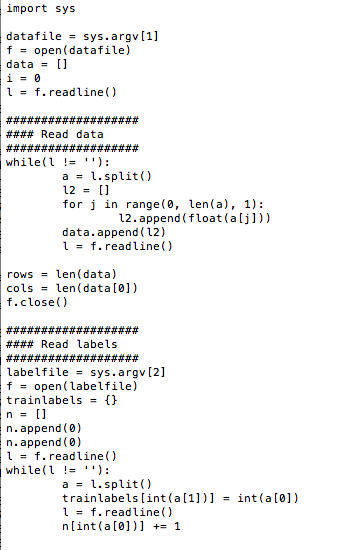
Nearest mean algorithm
Naive Bayes algorithm
Assignment 1
Predicted labels for naive bayes on breast cancer
trainlabels.0 mean initialized to 0.01
|
Kernel nearest means
|
09/16/2019
|
Nearest means in Python (part 1)
Nearest means in Python (part 2)
Datasets
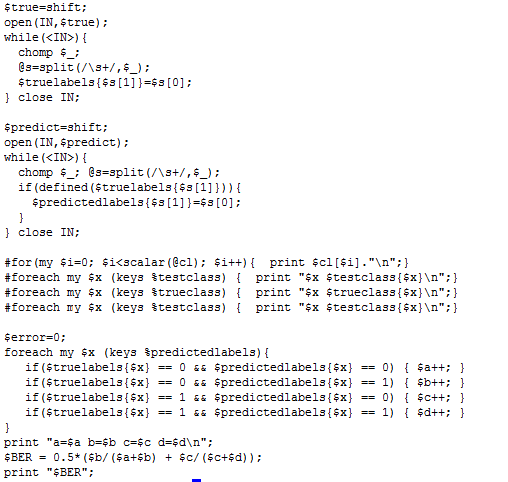
Balanced error
Balanced error in Perl
Kernels
More on kernels
Kernel nearest means
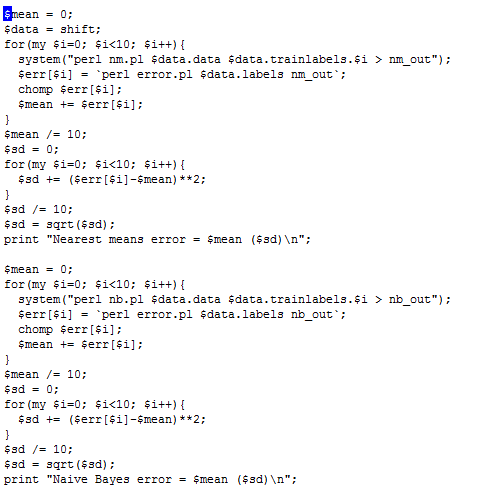
Script to compute average test error
Script to compute average test error
Textbook reading: 13.5, 13.6, 13.7
|
Separating hyperplanes and least squares
|
09/18/2019
|
Mean balanced cross-validation error on real data
Hyperplanes as classifiers
Least squares
Textbook reading: 10.2, 10.3, 10.6, 11.2, 11.3, 11.5, 11.7
|
Multi-layer perceptrons
|
09/25/2019
|
Multi-layer perceptrons
Assignment 2: Implement gradient descent for least squares
Predicted labels for least squares ionosphere trainlabels.0 training, eta=.0001, stop=.001
Least squares in Perl
Approximations by superpositions of sigmoidal functions (Cybenko 1989)
Approximation Capabilities of Multilayer Feedforward Networks (Hornik 1991)
The expressive power of neural networks: A view from the width (Lu et. al. 2017)
|
Support vector machines
|
|
Textbook reading: 13.1 to 13.3
Support vector machines
Assignment 3: Implement hinge loss gradient descent
Predicted labels for hinge loss on ionosphere trainlabels.0 training, eta=.001, stop=.001
Efficiency of coordinate
descent methods on huge-scale optimization problems
Hardness of separating hyperplanes
Learning Linear and Kernel
Predictors with the 01 Loss Function
|
More on kernels
|
|
Kernels
Multiple kernel learning by Lanckriet et. al.
Multiple kernel learning by Gonen and Alpaydin
|
Logistic regression
|
10/7/19
|
Logistic regression
Solver for regularized risk minimization
Textbook reading: 10.7
Assignment 4: Implement logistic discrimination algorithm
Predicted labels for logistic on climate trainlabels.0 training, eta=.001, stop=.001
|
Empirical and regularized risk minimization
|
10/9/19
|
Empirical risk minimization
Regularized risk minimization
Regularization and overfitting
Solver for regularized risk minimization
|
Mid-term exam review
|
10/14/19
|
Midterm exam review sheet
|
Mid-term exam
|
10/16/19
|
|
Feature selection
|
10/21/19
|
Assignment 5: Adaptive step size for least squares and hinge
Feature selection
Feature selection (additional notes)
A comparison of univariate and multivariate gene selection techniques for classification of cancer datasets
Feature selection with SVMs and F-score
Ranking genomic
causal variants with chi-square and SVM
|
Dimensionality reduction
|
10/23/19
|
Unsupervised dimensionality reduction
Dimensionality reduction (additional notes)
Proof of JL Lemma
Textbook reading: Chapter 6 sections 6.1, 6.3, and 6.6
Course project 1
Training dataset
Training labels
Test dataset
Python function to cross validate linear SVM C
|
Dimensionality reduction
|
10/28/19
|
Supervised dimensionality reduction
Maximum margin criterion
Laplacian linear discriminant analysis
|
| Decision trees, bagging, boosting, and stacking
|
10/30/19
|
Decision trees, bagging, boosting, and stacking
Decision trees (additional notes)
Ensemble methods (additional notes)
Assignment 6: Implement a decision stump in Python
Univariate vs. multivariate trees
Gradient boosted trees: Slides by Tianqi Chen
Textbook reading: Chapters 9 and 17 sections 9.2, 17.4, 17.6, 17.7
|
| Ensemble methods, random projections, and stacking
|
11/06/19
|
Stacking
Random
projections in
dimensionality reduction
Assignment 7: Implement a bagged decision
stump in Python
|
| Regression
|
11/11/19
|
Regression
Textbook reading: Chapter 4 section 4.6, Chapter 10 section 10.8, Chapter 13 section 13.10
|
Unsupervised learning - clustering
|
11/13/19
|
Clustering
Assignment 8: Implement k-means clustering in
Python
Tutorial on spectral clustering
K-means via PCA
Convergence properties of k-means
Textbook reading: Chapter 7 sections 7.1, 7.3, 7.7, and 7.8
|
Clustering
|
11/18/19
|
|
Clustering
|
11/20/19
|
|
| Feature learning
|
11/25/19
|
Extreme learning machines
Random Bits Regression: a Strong General Predictor for Big
Data
Exploring classification, clustering, and its limits in a compressed hidden space of a single
layer neural network with random weights
Learning Feature Representations
with K-means
Analysis of single-layer networks in unsupervised feature learning
On Random Weights and Unsupervised Feature Learning
Feature learning with
k-means
Course project 2
Random hyperplanes
Predicted labels of ionosphere on trainlabels.0 in the new feature space of
10K features (error=5.5%)
Results with random hyperplanes
|
| Time series data, text document classification, and other topics
|
12/02/19
|
Time series methods
Text encoding
Weekly sales transaction dataset (Time series contest)
Semi-supervised and self-supervised classification
Missing data (A study on missing data methods)
|
| Hidden Markov models
|
12/04/19
|
Hidden Markov models
Textbook reading: Chapter 15 (all of it)
|
| Big data
|
12/09/19
|
Big data
Mini-batch k-means
Stochastic gradient descent
Mapreduce for machine
learning on multi-core
|
| Comparison of classifiers and big data, ROC, multiclass,
statistical significance in comparing classifiers
|
12/11/19
|
Comparing classifiers
Comparison of classifiers
Do we Need Hundreds of Classifiers to Solve Real World Classification Problems?
An Empirical Comparison of Supervised Learning Algorithms
Statistical Comparisons of Classifiers over Multiple Data Sets
|
Some advanced topics and papers
|
|
Classification
boundaries(Code)
Convolutional neural networks for image recognition
Gradient based learning applied in document recognition
Representation learning
Geometrical and Statistical properties of systems of linear inequalities with
applications in pattern recognition (Cover 1965)
ImageNet
classification with deep neural networks (Krizhevsky et. al. 2012)
Random projections preserve margin
Random projections preserve margin II
Python Image Library
|
| Final review
|
|
Review of most things covered in the course
Final exam for review sheet
|
| Final
|
TBA
|
|
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}