Categories and Subject
Descriptors
I.7.2 (Automated Hypermedia);
H.5.1 (Hypermedia Information Systems)
This research provides system developers with the means to integrate hypermedia functionality into their applications with minimal or no alteration. This paper describes a hypermedia engine which executes concurrently with, but independently of, information system applications, automatically providing their users with both access to the application's interrelationships and supplemental navigation facilities. Our approach contributes especially by serving systems which dynamically generate their display contents, which includes most business and engineering analysis applications. Applications remain entirely hypermedia unaware [Bieber 1992; Kacmar 1995; Puttress and Guimaraes 1990]; the engine manages all interrelationship access and navigation on the application's behalf. Current hypermedia engines either require an application to incorporate hypermedia functionality directly into its feature set, or provide only manual linking within applications that retrieve and display preexisting information.
We would be remiss not to note the World Wide Web's success in bringing attention to the hypermedia concept. Despite this success, the Web's HTML and XML data models are not as rich as other hypermedia data models and Web browsers generally implement only a rudimentary set of hypermedia features [Bieber et al. 1997]. Most Web applications either require users to create hypermedia links manually within their HTML documents or require the application to be rewritten to incorporate hypermedia links and accommodate the Web interface. Our work presents an alternate approach to hypermedia integration on the Web. Web browsers and the few WYSIWYG Web editors could serve as the user interface system in our engine's architecture described in §3.1.
In terms of open hypermedia systems research (see §2.3), our work contributes a standard generic wrapper for back-end or storage level components-in our case applications which dynamically generate content. (We call these dynamically-mapped information systems or DMISs.) The wrapper automatically maps hypermedia constructs to applications contents. The hypermedia engine delivers hypermedia support based on these mappings. To the extent that other open hypermedia systems support DMISs, they do so on a case-by-case basis instead of in a standard way, they only support limited domains, or they only map hypermedia to the display values as opposed to the objects underlying these display values. §2.3 elaborates on these distinctions.
We begin the next section
by examining the interrelationships inherent within application domains.
Few applications give users full access to the entire range of interrelationships.
We elaborate on the requirements distinguishing dynamically-mapped information
systems (DMISs) from display-oriented applications. DMISs dynamically generate
content and require automated dynamically-mapped hypermedia support. We
then review the current state of hypermedia integration support. Section
3 introduces our implementation architecture and describes our prototype
for a mathematical modeling system. Section 4 reviews our future plans
and sets a research agenda for hypermedia support of everyday applications.
(1) Identifying relationships:
What characterizes a useful relationship?
Assume the user selects
an item of interest in a computer display. Each of the following eight
general kinds of relationships represents some aspect of that item. When
implemented, it will give the user direct access to it. Of course, different
relationships will serve different users such as application developers,
managers, analysts and customers. Good implementations will filter and
tailor the set of relationships for a given user and task. §3.5 gives
examples of each for TEFA, our example DMIS application.
Process Relationships
Process relationships represent
processes. In a work flow support system or ESS, process relationships
represent the interconnections among workgroups, departments and software
applications handling different aspects of a product or service. Process
relationships give access to the next step in a work flow or procedure,
subtask in a project management system, or document in a series.
Operation Relationships
Operation relationships
include executable commands (e.g., menu commands), logically connecting
an object to the result of operating upon it. In a DSS for example, an
execution link connects a decision model and data scenario with their computed
analysis result. An explanation link connects that analysis result with
an explanation of its calculation.
Structural Relationships
Structural relationships
connect related objects based on the application's domain independent internal
structure common to all instances of the application system. In every DSS
these include links among a decision model's equations, its variables,
and individual data values instantiating the variables. In every project
management system, subtasks are related structurally to their parent tasks,
to the portion of the timeline that they affect, and to documents produced
within them. In every geographic information system (GIS), the elements
of a map and their underlying data are related structurally. In every programming
language editor, program variables are related structurally to all statements
that contain them. Subroutines are related structurally to the statements
that call them. In every spreadsheet, formulas are related structurally
to the cells and functions they include.
Descriptive Relationships
Descriptive relationships
connect an item of interest to definitions, longer descriptions, an object's
purpose and other descriptive information.
Information Relationships
Information relationships
connect an item of interest to its attributes and parameters and other
background information. In a DSS, a data value's system parameters include
its size, data type and security classification. Its domain parameters
include its attributes. Background information includes its source and
owner and purpose. Descriptive information also encompasses definitions,
longer descriptions and background information.
Occurrence Relationships
Occurrence relationships
connect all views and other manifestations of a given item. In a CASE tool,
for example, these would connect each occurrence of an item in the requirements
document, design documents, program code, documentation and system output.
In a GIS, one should be able to see every occurrence of a data value or
geographic object in all maps, data listings and analysis reports. Occurrence
relationships would also link different versions of the same document or
datum.
Contingent or Ad Hoc Relationships
Contingent or ad hoc relationships
represent all relationships declared by the user in addition to those above.
While all the aforementioned relationships could be generated automatically
based on the application or system structure, ad hoc links allow the user
to declare anything not inferable or automatable. They thus are contingent
on synthesizing abilities and knowledge the user has but the computer does
not. Contingent relationships range from comments on single items to user-declared
links among items. Both document authors (e.g., analysts) and, security
permitting, document readers (e.g., other group members, management, customers
and the general public) may be able to annotate items within an application.
Note that these are general kinds (classes or categories) of relationships one finds in different computational applications. Various hypermedia researchers have come up with different link taxonomies [Trigg and Weiser 1986; Wang and Rada 1995; Oinas-Kukkonen 1996] which contain specific link types for particular applications or domains. These could fall across several of our general link categories. Note too that we have compiled the above set of general link categories based on personal experience in developing and using applications. It is not complete. Neither have we tried to normalize it; a particular semantic link type might fall in more than one category. Nevertheless we have found the current set very useful in thinking about providing relationship management support to analytical computer applications. As part of our future research we plan to come up with a more complete and theoretically robust taxonomy of link categories. Although we have found other general taxonomies [DeRose 1989; Parunak 1991a; Rao and Turoff 1990] inadequate for our domain of generic application support, we might incorporate and use them as a starting point.
(2) Which items should
have these relationships?
Taking a "user knows best"
viewpoint prescribes making every object on the computer screen selectable-data
values, calculation results, labels, titles, report text, entire documents,
and so forth-and therefore a candidate for annotation and other relationships.
Furthermore, users could access meta-level relationships: every relationship
listed above could apply to its own type and to every other. For example,
team members should be able to annotate each others' annotations. Users-especially
developers within a hypermedia-supported development environment-should
be able to annotate a structural relationship or see which processes are
interrelated. Similarly, they should have access to all occurrences of
any relationship in the system.
Providing such information supports the goal of many organizations to empower lower-level employees with decision-making capabilities. On the other hand, in certain domains developers may deem such access irrelevant or even distracting to the user's task, possibly slowing down time-critical operations. Thus, while a hypermedia analysis helps developers think about an application more broadly, in the end the developer must decide which additional information is (in)appropriate.
(3) How should users access these relationships and the items they associate?The user typically selects an item on the computer screen to follow its link or chooses from a list of available links. (One may have to rank, filter or layer links if their magnitude overwhelms the user.) If a link's purpose or destination is not intuitive, its author or the system builder should label it in some way. Hypermedia access includes navigation, annotation and view-oriented features. Together, these features constitute what we call "full hypermedia functionality," an ideal level of functionality that few of today's hypermedia systems-including our own-achieve. Many systems calling themselves "hypermedia systems," in fact, provide only forward navigation through direct manipulation, and perhaps commenting [Littleford 1991; Rizk and Sauter 1992].
Navigation transports the user among information items. Its features include browsing (following a relationship's link), backtracking, information retrieval-style query based on content, and query based on interrelationships [Halasz 1988; Lee et al. 1996; Bieber and Vitali 1997; Bieber et al. 1997]. Annotation includes comments, bookmarks (hot list items) and user-declared contingent links. In a DSS, for example, annotations can provide justification for a course of action that a decision-maker takes [Bieber 1992]. Users normally traverse from node to node at the detail level, i.e., with each node occupying a window on the screen. View-oriented features enable users to navigate via (graphical) overviews [Landow 1990; Utting and Yankelovich 1989] of the hypermedia network. Overviews help alleviate the network disorientation [Conklin 1987, Thüring et al. 1995] associated with hypermedia's nonrestrictive, user-directed access. View-oriented features also include navigation along recommended paths (trails) [Trigg and Weiser 1986] and guided tours [Marshall and Irish 1989; Garzotto et al. 1996a] of interrelated items. Trails and guided tours both direct and constrain forward navigation. They can document analyses or serve as tutorials, and can be tailored for specific users or tasks. An analyst, for example, could prepare an annotated guided tour to explain a completed analysis or other process. Bieber and Kacmar [1995] describe these hypermedia features in greater detail, especially for computation-oriented applications (i.e., dynamically-mapped systems or DMISs-see §2.2 below), using a geographic information system as the example domain. For a comprehensive overview of hypermedia concepts and functionality see [Bieber et al. 1997; Conklin 1987; Nielsen 1990, 1995].
(4) Structuring Related
Information for Comprehension
Hypermedia, as a concept,
encourages authors to structure information as an associative network of
nodes and interrelating links. This frees authors from the linear, sequential
structure that dominates most printed documents. Presenting information
as an associative network enables readers to access information in the
order most appropriate to their purposes, freeing them from obeying the
linear ordering implied within printed documents. Many hypermedia implementations
also allow readers to become authors (temporarily, at least) by adding
comments (annotations) and additional links among what they read [Conklin
1987]. In all these ways hypermedia promotes options and choice.
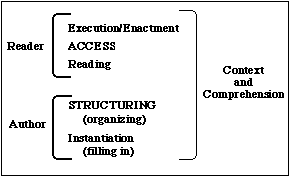
In a larger sense, hypermedia increases comprehension [Rana and Bieber 1997; Thüring et al. 1995]. (See Figure 1.) Through the process of structuring information as an associative network (i.e., both creating an organizing structure and then instantiating content into this structure), authors often come to understand that information better. Readers build up a mental model of the information from navigating within the structure and reading content. For readers, comprehension increases through the enriched context that comes from the multiple supplemental relationships which hypermedia encourages authors to provide around a piece of information. Readers build context through browsing these relationships and through other sophisticated navigation support, such as overviews, trails and history support. (Oinas-Kukkonen [1997] extends this framework, considering hypermedia as a technique for enhancing communication between authors and readers.)
Hypermedia structuring extends beyond traditional authored content. Some system developers model processes as associative networks which users invoke through navigating. Representing the process steps as nodes and transitions as links enables developers and users to augment the process with annotations and with links to related information [Noll and Scacchi 1996; Scacchi 1989]. Similarly, some developers structure programs as associated networks controlling which links to activate based on the user's previous interactions (e.g., petri-nets [Stotts and Furuta 1989]). Invoking or performing the process is a reader activity. Authors create programs and processes as part of structuring and instantiating.
While many people only think of hypermedia in terms of enriching authoring and reading environments for manually-crafted documents, hypermedia structuring and access also enhance context and comprehension for environments in which hypermedia functionality is generated automatically. In both cases hypermedia can give direct access to a rich context or web of related information around an object of interest.
---
Two important consequences
for systems development follow from the hypermedia concept. First, we can
define hypermedia both as the science of relationships [Isakowitz et al.
1995] and as a technology for information access and relationship management.
Second, a hypermedia philosophy or vantage point emerges for thinking about
applications. As we stated earlier, a hypermedia philosophy helps us think
about a system in terms of the relationships among its elements and processes,
focusing on how users gain access to them. (Oinas-Kukkonen [1997] discusses
many of these issues further.) Thus, hypermedia analysis could supplement
the developer's standard design methodology, broadening the scope of objects
and relationships a system encompasses. In fact, we believe that a hypermedia
analysis should play a part in the design of every application with user
interaction. In addition, hypermedia functionality could supplement a system's
feature set. This paper does both, applying a hypermedia analysis to our
example domain of model management and embellishing information systems,
in general, with automated hypermedia functionality.
In the following subsections
we describe our focus of dynamically-mapped information systems and describe
several techniques for incorporating hypermedia into them. Then in §3
we describe our own architecture and show how hypermedia has enriched the
information generated within its dynamically-mapped applications.
We model DMISs as having two logical parts: a computational portion and an interface portion. DMIS application content is produced (generated or retrieved) in the computational portion and displayed in the interface portion. As we shall see in §3, the hypermedia mapping takes place as messages pass from one to the other.
DMISs present the special challenge of dynamic regeneration. Suppose an analyst wants to determine the changes in projected profits for different sales levels. He or she performs the analysis and makes comments on each resulting profit calculation. A few days later, when preparing his final report, he needs the calculation results and comments. He wishes to return to them without having to remember the parameter values and then manually re-performing each calculation. Luckily he created a bookmark to each calculation result before discarding them. A bookmark is a one-way link from a globally-accessible menu to something the user wishes to find again-in this case the calculation result. Invoking each bookmark causes the DMIS to reexecute its calculation(s) automatically, and to locate its comment automatically. Bieber and Kacmar [1995] present additional examples of dynamic regeneration for geographic information systems.
To support DMISs we map hypermedia links for a DMIS element based on its internal identity, not to its display value. A stock's price, for example, can change, but the stock's identity never does. Thus we would have to attach the aforementioned bookmarks and comments to the calculation result's internal identifier, not to its display value. This is mandatory for determining what to regenerate, e.g., when the user chooses a bookmark. It also is mandatory for finding link endpoints in displays. There may be multiple instances of the same number in a display with only one of them representing a particular stock's or calculation's value.
During the recent Hypertext'97
Conference, Wendy Hall and Ted Nelson coined the terms flink and
flinking, which neatly describe our approach to linking. Flinking
stands both for "flinging links" and "filtering links." Flinks are "flung
links" or "filtered links." Essentially we have produced a hypermedia engine
that takes an application document and throws a set of links on top of
it. Thus the links do not reside in documents; they are determined by some
external process or agent. Furthermore, lest the set of links flung at
the document overwhelm the user, we must filter out the inappropriate ones.
Thus one feature that distinguishes ours from the other techniques we discuss
in the following section, is that our approach supports domains that generate
content in real-time and therefore require dynamic flinking.
Hypermedia data models
Several hypermedia data
models, such as the Hypertext Abstract Machine (HAM) [Campbell and Goodman
1988], Dexter [Halasz and Schwartz 1994] and the World Wide Web's HTML
provide data structures and guidelines for constructing nodes, links and
anchors, and for browsing. Builders can implement one of these instead
of making up their own. For example Neptune, a hypermedia CAD application,
implements HAM [Delisle and Schwartz 1986]. DHM [Grønbæk et
al. 1994] implements Dexter, and RHYTHM [Maioli et al. 1993, 1994] and
Wan's hypermedia support for relational database management systems [Wan
1996; Wan and Bieber 1997] implement extensions to Dexter. World Wide Web
browsers render HTML. HyTime [International Standards Organization 1992;
Newcomb et al. 1991] provides an SGML-based ISO standard model for hypermedia
documents (as well as musical documents), although its complexity has encouraged
but a few implementations [Buford 1996]. Implementing a data model is no
easy task, but it does provide a solid starting point for a hypermedia
system.
The toolkit approach for
individual applications
The toolkit approach facilitates
incorporating hypermedia functionality into individual non-hypermedia applications
being built from scratch. An application builder embeds calls to the toolkit's
subroutine library in the application's code. Examples of toolkits include
Puttress and Guimaraes' Hypertext Object-oriented Toolkit [1990] and the
Andrew Toolkit [Sherman et al. 1990]. Anderson [1996] extends the JAVA
ATW user-interface toolkit with hypermedia-aware widgets. His approach
integrates the toolkit with the Chimera open hypermedia system [Anderson
et al. 1994; Anderson 1997] such that the widgets become Chimera clients
at run-time. Any interface using these widgets automatically gets a basic
set of hypermedia functionality (e.g., make anchor, start link, end link).
The application developer then writes event handlers to respond to the
hypermedia operations these widgets provide. Garrido and Rossi [1996] are
extending the VisualWorks Smalltalk palette to include hypermedia-aware
widgets.
Hyperbases
Builders constructing hypermedia
systems from scratch need to store and retrieve hypermedia constructs (nodes,
links and anchors), which persist between user sessions. Hyperbase storage
engines such as HB3 [Leggett and Schnase 1994] provide a data store and
management routines for hypermedia constructs akin to database management
systems. System builders can integrate hyperbases into their systems, as
many link services and open hypermedia systems do.
Link services for linking
among applications
Several research efforts
have succeeded in creating links among primarily non-hypermedia information
systems and in facilitating their traversal. The Sun Link Service [Pearl
1989], HyperBase [Schütt and Streitz 1990], Microcosm [Davis et al.
1992], Multicard [Rizk and Sauter 1992], PROXHY [Kacmar and Leggett 1991],
SP3 [Leggett and Schnase 1994] and Chimera [Anderson et al. 1994; Anderson
1997] each has a hypermedia link service that executes concurrently with
external systems and provides linking support. Each of the seven hypermedia
systems expects client information systems to support anchor creation and
selection by embedding hypermedia calls and handling minimal hypermedia
functionality in a manner similar to the toolkit approach. The latter five
systems also provide multiple levels of hypermedia navigation and annotation
support, based on the degree of hypermedia compliance the client
non-hypermedia information system provides. Each also provides a limited
set of support for client systems that are not hypermedia compatible at
all, as we discuss in §3.6. All systems, however, concentrate primarily
on supporting manual linking within display-oriented systems.
Generating hypermedia
applications from a hypermedia design methodology
Hypermedia design methods
present one of the most important developments in the hypermedia field
[Bieber and Isakowitz 1995, 1996; Fraïssé et al. 1995]. This
involves more than applying well-understood system analysis and design
or software engineering techniques to hypermedia. Hypermedia functionality
requires new kinds of relationship management and navigation support. Hypermedia
design methods provide a systematic approach to relationship management
and navigation support, which in turn, should enable consistent, large-scale,
robust hypermedia implementations. The most advanced design methodology,
RMM [Isakowitz et al. 1995, 1997], has software called RMCASE, which can
generate a display-oriented standalone hypermedia application [Diaz and
Isakowitz 1995; Diaz et al. 1995]. The designer must model his or her application
in terms of entities and relationships; RMCASE then generates a standalone
application with the structural and associative links specified in the
entity-relationship design (but no others, including no manual linking).
Lange [1996] has built software on top of ONTOS for his object-oriented
Enhanced Object-Relationship Model design methodology. Other design methodologies
such as HDM [Garzotto et al. 1993] and OOHDM [Schwabe et al. 1996] have
no accompanying software for generating the application once designed.
All these design methods produce new hypermedia applications, complete
with their own interface. Our approach differs in that it supports new
or existing DMIS applications, without requiring hypermedia-oriented relationships
or features to be embedded in the application code.
Hypermedia application
software
For standalone applications,
many commercial and research hypermedia application environments exist.
Here are just a few. The MacWeb design environment produces a hypermedia
application for knowledge-based systems [Nanard and Nanard 1995a]. VIKI
enables users to build spatial hypermedia applications in which all links
are implicit through the user's spatial location of nodes [Marshall et
al. 1994; Marshall and Shipman 1995]. These often support only manual hypermedia
linking, though some such as KMS [Akscyn et al. 1988] and servers for World
Wide Web browsers may be extended through a scripting language.
Independently executing
hypermedia engines
Hypermedia engines execute
independently of an application with minimal modifications to it, and provide
the application's users with hypermedia support. (This differs from but
clearly relates to a data model definition of engines-providing "abstract
hypermedia data models and storage functionality" to applications [Bapat
et al. 1996].) Few approaches provide transparent hypermedia integration
as our engine does. Notable projects include Microcosm's Universal Viewer
[Davis et al. 1994], Freckles [Kacmar 1993, 1995] and the OO-Navigator
[Garrido and Rossi 1996; Rossi et al. 1996]. The Universal Viewer gives
users access to a minimal level of Microcosm's hypermedia functionality
through the PC Windows operating system. It places selectable buttons in
the title bar of the application's windows. Users can select text in these
unaware applications and select a Microcosm button to check for "generic"
or "keyword" links originating from any portion of the text selected. Links
to these applications will launch the application under the Universal Viewer
and open the destination document within it.
Kacmar's [1993] work focuses on hypermedia-aware interfaces. His engine works together with the interface to determine how to display objects. The hypermedia engine handles linking and traversal. The interface allows users to select anchors and display the results of traversals. The underlying back-end application must be implemented so that it returns an object's contents when requested. Kacmar's work differs from ours, in part, through its philosophy. His work aims at generating hypermedia-aware interfaces, where our work eventually should lead to hypermedia-unaware interfaces as well as hypermedia-unaware DMISs. Currently the limitations to our approach described in §3.6 prevent an entirely hypermedia-unaware interface, which Microcosm's Universal Viewer and Kacmar's second project [1995] have achieved, at least for non-DMIS applications.
In the second project related to our work, Kacmar [1995] has developed another version of his architecture which operates entirely independently of the interface system. It uses the underlying UNIX twm X Windows system to overlay all hypermedia controls (nodes, anchors, menus, etc.). As with the Universal Viewer, it remains unaware of the application's data model and object identifiers. It uses the window title, as a structured object descriptor, to associate an identifier with the window's contents. Window contents are maintained by the underlying application.
All three approaches seamlessly support an application's other functionality but provide only manual linking-in the Universal Viewer's case on an object's display value; in Kacmar's first system on the object identity; and in Kacmar's second system, on the object's fixed location within a recognized window. Our hypermedia engine, in contrast, contributes by providing seamless, automated supplemental navigation and interrelationship access to dynamically-mapped information systems.
The OO-Navigator comes the closest to our approach, providing a seamless hypermedia support for computational systems that execute within a single Smalltalk environment. They provide a hypermedia layer above the applications which maps application classes to node classes, and relationships among classes to link classes. From these mappings the OO-Navigator automatically generates nodes and links. As mentioned earlier, the OO-Navigator uses Smalltalk's interface modified with hypermedia-aware widgets [Garrido and Rossi 1996]. This approach meets our goal of supplementing Smalltalk applications with hypermedia support without altering them. Our approach applies to both object-oriented and non object-oriented applications.
Open Hypermedia Systems
An open hypermedia system
(OHS) combines a link service and a hyperbase, providing linking services
to applications [Whitehead 1997; Wiil 1997; Wiil and Demeyer 1996]. Grønbæk
and Wiil [1997] present an OHS reference architecture which inherits features
from several important OHS models-the Flag Taxonomy [Østerbye and
Wiil 1996], the Dexter-based Devise Hypermedia framework [Grønbæk
et al. 1994], the Shim Architecture [Davis et al. 1996] and the extended
HyperDisco model [Wiil and Leggett 1996]. Figure 2 shows their proposed
OHS reference architecture.
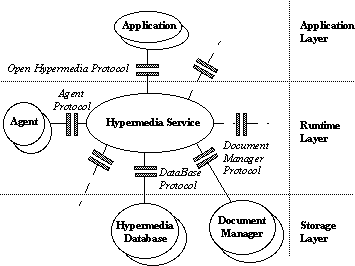
OHSs predominantly provide
manual linking services to display-oriented applications. A few claim to
support DMISs, but none do this in a systematic manner-all such integration
is done ad hoc on a case-by-case basis. For example, in introducing
his architectural model for OHS integration, Whitehead [1997] states that
"a complete integration consists of a user interface for manipulating anchors
and links, and an unbroken path for communication between the {user interface}
application and the open hypermedia system." The architectures we propose
in §3.1, §3.7 and §3.8, and Chiu's [1997] specialization
of them for the World Wide Web provide a systematic way (bridge laws and
well-defined DMIS wrapper support) to provide dynamic mapping services
for DMIS applications within an OHS. Chiu proposes seven features for OHS
support of DMISs: integration with display-oriented applications, integration
with DMISs, support for networked distribution, multiple independent users,
collaboration, and cross-platform systems, and the ability to extend the
OHS (e.g., with a scripting language). He also presents survey results
showing how well several OHSs meet these goals.
Our research takes the following approach. Hypermedia functionality and interrelationship access supplement the application's normal operations. In terms of information representations, we need to model hypermedia data structures, hypermedia navigation structures, and if not otherwise available, application metainformation and the application internal structure (i.e., its design or schema). All are critical for automated dynamic mapping. In keeping with our goal of altering applications as little as possible-Kacmar and Leggett [1991] call this a "minimal cost" strategy-we do not alter the application's existing data or access structures, but we must be able to interact with them. The mapping, in turn, is critical for retrieving information, i.e., user access. Our engine builds hypermedia functionality on top of the hypermedia data structures using this mapping. The richer the data representation, the more detailed the mapping. This, in turn, affects both the types of navigation available and the types of interrelationships we can infer automatically. The engine uses a relatively simple hypermedia data model consisting of nodes, links and link markers-buttons or anchors. Each carries a rich and flexible set of attributes for capturing the semantic and behavioral aspects of the application elements it represents. Wan has developed a more sophisticated data model for modeling application elements at a higher level and has applied these to relational database management systems [Wan 1996; Wan and Bieber 1997]. We may apply this work in future versions. Bridge laws specify the actual mapping between each type of application element and its equivalent hypermedia construct. Bridge laws are logical rules for mapping two independent representational domains [Kimbrough 1977; Bieber and Kimbrough 1992, 1994], in our case model management and hypermedia.
Mapping and retrieval occur as follows. Our engine intercepts all messages passing from the computational portion of an application to the interface, and uses bridge laws to map each appropriate element of the message to a hypermedia node, link or anchor. Users interact with these hypermedia representations on the screen. If the user selects a normal application command-we map these to the operation relationship links described in §2.1-the hypermedia engine passes the command on to the application for processing. If the user selects a hypermedia engine command (such as a menu command to create an annotation), the hypermedia engine processes it entirely. If the user selects a supplemental schema, process, operation, structural, descriptive, information or occurrence relationship, the engine infers the appropriate application commands, meta-application operations (e.g., at the operating systems level or schema level) or hypermedia engine operations that will produce the desired information. If the user selects a contingent (ad hoc) relationship, the hypermedia engine retrieves the annotation. The interface also handles all other interaction with the DMIS application, such as form-filling and directly manipulating DMIS objects. Thus users access the entire functionality of the DMIS as well as the supplemental hypermedia features through the independent front-end interface system.
Regarding delivery, our engine currently serves applications which can use an independent front-end interface system, such as those which provide an application programming interface (API). We need to use a front-end that can display selectable hypermedia link markers. World Wide Web browsers qualify and indeed we are currently reimplementing our architecture for the Web. As we describe in §4, we plan to extend our engine to existing application interfaces.
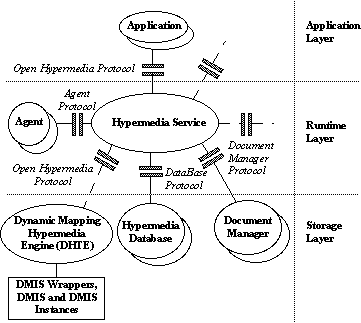
This section describes our
architecture and our current prototype. We begin in §3.1 with our
overall conceptual dynamic-mapping hypermedia engine (DHTE) architecture.
§3.2 describes the engine's bridge laws. To jump-start our work, we
took advantage of an existing display-oriented hypermedia engine, Microcosm,
into which we integrated our DHTE. §3.3 describes Microcosm. §3.4
describes both our integration architecture and our prototype for the model
management application, TEFA. §3.5 demonstrates how our prototype
provides TEFA with many of the interrelationships described in §2.1.
§3.6 describes limitations to our approach. §3.7 gives a glimpse
of our final research goal: a multi-user, multi-application distributed
DHTE architecture. §3.8 concludes by showing how we might integrate
DHTE with other OHS to give them dynamic mapping abilities.
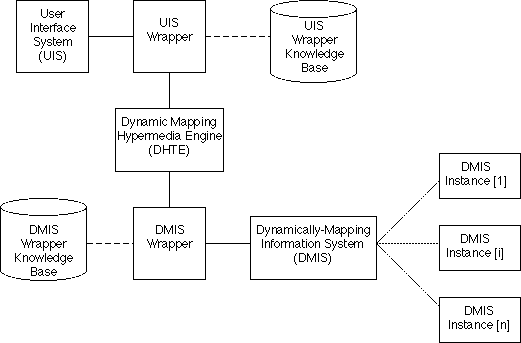
User Interface System
(UIS)
The user interface system
is the "viewer", i.e., the front-end interface through which the user accesses
the application and hypermedia functionality.
UIS Wrapper
The UIS wrapper serves three
important functions. First it translates messages from the DHTE's standard
format to something the UIS can process, and vice versa. Second, it passes
messages between the two systems. Third, it buffers the UIS, implementing
any functionality the engine requires of the UIS, which the UIS cannot
provide itself [Whitehead 1997]. For example, as we discuss in §3.6,
the engine requires the UIS to track application elements on the screen.
If the UIS does not have this capability, the wrapper may keep track of
the location of each element on behalf of the UIS. The term "wrapper" is
analogous to "adaptors" and "mediators" in the design pattern literature
[Gamma et al. 1995]. Some of the OHS literature calls wrappers "shims".
UIS Wrapper Knowledge
Base
The UIS Wrapper knowledge
base contains the information the UIS wrapper needs to communicate with
its UIS. In it, the UIS wrapper maintains communication formats, current
parameter settings and any routines necessary to maintain the level of
coordination the DMIS requires of the UIS.
Dynamically-mapped Information
System (DMIS)
The DMIS is an application
which dynamically generates the contents of its displays, or otherwise
requires the hypermedia engine to map hypermedia for it automatically at
run time.
DMIS Instances
These are the individual
programs, worksheets or whatever other application instances that run under
the DMIS system. For example, an expert system shell or relational database
management system (RDBMS) would be a DMIS whereas the expert systems written
in that shell or the databases manipulated by the RDBMS would be DMIS instances.
DMIS Wrapper
The DMIS Wrapper serves
the same three functions as the UIS Wrapper. If necessary, it identifies
and marks elements in the DMIS messages to which hypermedia components
are mapped [Bieber 1995]. It also defines the routines for determining
the interrelationships defined in §2.1. The DMIS wrapper is the key
to integrating the DMIS with minimal changes. If the DMIS wrapper can be
written to interact with a DMIS's API, then the DMIS will remain entirely
unaltered.
DMIS Wrapper Knowledge
Base
The DMIS Wrapper Knowledge
Base contains the set of bridge laws describing the DMIS' internal structure.
It contains network access information for each DMIS so the wrapper can
route messages to it and receive messages from it. The knowledge base also
contains routines for constructing messages for the DMIS and parsing its
responses.
Dynamic Mapping Hypermedia
Engine (DHTE)
The engine implements all
hypermedia navigation and inference on behalf of the DMIS. The DHTE communicates
with all DMISs through a single message format and all UISs with another,
single message format. (Currently the open hypermedia systems research
community is trying to develop a single protocol for all open hypermedia
systems to use [Davis et al. 1996]. As we describe in §3.8, we may
adopt this protocol in the future.) The wrappers convert from these standard
message formats to ones the DMISs or UISs can use. In [Bieber 1995] we
proposed a logical structure for the DHTE consisting of the six knowledge
bases summarized as follows. §3.4 lists the actual DHTE modules in
this implementation.
Hypermedia Knowledge Base: All hypermedia information registered by users including annotative links, guided tours and trails. The hypermedia engine maintains these independent of the DMIS elements upon which they are based.
Bridge laws describe a DMIS' internal structure adequately to map DMIS instance components to hypermedia constructs. The engine uses three kinds of bridge laws. An identifier bridge law determines what kind of component the user has selected and to which DMIS it belongs. The set of DMIS link bridge laws determines the types of schema, process, operation, structural, descriptive, information or occurrence relationships available for that type of component. Link bridge laws also list any commands which the DMIS or its wrapper should execute to determine the relationship's destination. Each bridge law captures one of these relationships for a type (kind or class) of DMIS component. The engine uses the bridge law specifications to map its relationship as a hypermedia link. The user then chooses among the set of possible links. Upon choosing one, the engine invokes the commands associated with its link bridge law. If a contingent link leads to a DMIS instance component not currently on display, a regeneration bridge law determines the commands and parameters necessary for invoking the DMIS to regenerate it.
The person who knows the DMIS the best-the systems programmer who builds or maintains it-should develop its bridge laws. Because bridge laws are based on the DMIS' internal structure, and each instance shares this structure (e.g., each worksheet written in a particular spreadsheet package shares the same internal structure), the DMIS wrapper will only need one set of bridge laws to serve all of its DMIS' instances. Similarly, all the designs or schemata representing the actual components of each of a DMIS' instances, which the engine uses to determine schema relationships, will share the same internal structure. Thus, once in place, the bridge laws enable the DHTE to map a hypermedia network to any DMIS instance. Instance builders and their users need have no knowledge of bridge laws. To them, hypermedia functionality occurs automatically!
We represent bridge laws and other system knowledge as logical predicates, and we have programmed our engine prototype in Prolog to process them. DMIS wrappers thus must provide the engine with the bridge laws formatted as (perhaps translated into) logical predicates. All arguments beginning with upper-case letters are variables. While Prolog can be used to instantiate (infer the value of) any argument, generally the first one or two arguments already will be instantiated and thus act as the "key" for instantiating the other arguments. While we specify each predicate as a logical fact here, DMIS developers can specify each as logical rule with arbitrarily complex inferencing. As part of our future research, we hope to accept bridge laws specified other than in predicate logic, or at least enable one to construct them in a more builder-friendly bridge law editor.
We now show four Prolog predicates to illustrate our general approach to mapping DMIS application components. §3.4 describes the process in more detail. The hypermedia engine instantiates the following predicate (fact) for each component (document, link marker, link, etc.) which it passes to the UIS for display and stores it in the Active Knowledge Base. The engine's internal engine component identifier is the key to determine which DMIS the component is from and the identifier by which the DMIS knows it.
(2) Determine every structural element within the DMIS (i.e., those generic classes of elements found in all DMIS instances for this DMIS).
(3) For each of these elements, determine all possible interrelationships. Include interrelationships within the DMIS, to elements outside the DMIS, and among DMISs connected by the hypermedia engine (see §3.7). Use the list of relationships from §2.1 to help think of these.
(4) For each element, also determine all possible types of metainformation, both within and outside the envisioned DMIS and instance. (This may lead the developer to include this additional information in the DMIS or at least provide mechanism to link to it.)
(5) Write one identifier and regeneration bridge law for each structural DMIS element, i.e., for each class of DMIS elements. Also include a regeneration bridge law for every type of document the DMIS produces. This will require determining the set of DMIS commands to retrieve or regenerate any element within the DMIS.
(6) Write one link bridge law for each interrelationship or type of metainformation. Determine the commands to implement any behavior to execute when a user selects a link (such as with operation relationships). If the link endpoint needs to be retrieved or generated, ensure that identifier and regeneration bridge laws exist for that endpoint.
(7) Write the DMIS wrapper. Ensure that it can capture each kind of communication the DMIS's API (or computational part [Bieber and Kacmar 1995]) sends to the user interface. The DHTE will have to determine the elements inside any display information so it can map these to hypermedia components using the bridge laws. The wrapper should include network routing information so the DHTE can find the DMIS. The wrapper also must provide any routines necessary for the DMIS to comply to DHTE expectations, as outlined in §3.6.
One therefore should plan to filter these interrelationships to the appropriate user. For example, links to parametric information and low level descriptions only should be highlighted for programmers debugging an application or authors considering reusing parts of the application in future applications. Carr et al. [1995] have developed the Web-based Distributed Link Service, which manages different sets of links for different contexts. Users can choose which sets of links to activate. We are considering achieving a first level of filtering by separating bridge laws into separate groups, each representing a particular context. We would activate only certain groups of contexts at any given time according to the user's current role and task. (Brusilovsky [1996] and Calvi and De Bra [1997] use the alternate approach of adaptive linking for activating and deactivating links. We shall consider this approach as well.) Filtering is a high priority for our future research.
Together, our hypermedia data model of nodes, links and link markers, and its bridge laws provide a comprehensive logic-based knowledge representation that enables the DHTE engine to reason about the components (models, data, commands, etc.) of the underlying information systems they map. For further information on bridge laws, see [Kimbrough 1997; Bieber and Kimbrough 1992, 1994]. Also, Wan developed a different model of bridge laws, which focuses on a component's structure and its surrounding components, based upon the Dexter model (see §2.2) [Wan and Bieber 1996; Wan 1996]. Wan's work complements our approach. Its contributions lie in providing a fuller and more formal model of generalized hypermedia, which includes composite constructs.
We currently are revising
link bridge laws to be more tailorable and flexible, and to better serve
the distributed multi-application environment described in §3.7. Link
bridge laws will comprise six sub-specifications. This new format recognizes
that the DHTE will be able to do some link determination on its own, and
that it might have to consult the DMIS wrapper for more complex link determination.
The DMIS wrapper, in turn, may have to invoke the DMIS itself for some
link determination.
(b) the Link's Condition
List
The set of conditions will
determine whether to return a link using this bridge law when the user
has selected an object of the bridge law's component type. This will include
conditions which the DHTE hypermedia engine can determine, as well as conditions
the DMIS wrapper can determine (perhaps by invoking routines in the DMIS
itself). If calculating some of these conditions proves to be complex and
time-consuming, then the routines to calculate the conditions should include
an indication of how much processing they require. The DHTE might decide
to include this bridge law's link provisionally in the set of available
links instead of making the user wait until condition determination completes.
(c) Routines to Determine
Available Links
The DHTE or DMIS wrapper
executes these routines to determine which link this bridge law returns
to be included in the set of available links.
(d) Routines to Execute
when the User Selects the Link
The DMIS wrapper will invoke
these routines to traverse/execute the link once the user has selected
it from the set of available links. This also could include an indication
of how much processing is necessary to traverse or execute this link.
(e) the Link's Display
Label
The display name of the
link when listing it in the available link set.
(f) the Link's Semantic
Type
The semantic link type of
the link this bridge law returns.
(g) The Link's Destination
This routine determines
the destination endpoint's identifier for the link this bridge law returns.
It also could include an indication of how much processing is necessary
to determine this identifier.
Now we turn to our prototype.
Instead of implementing our architecture from scratch, we built on an existing,
non dynamically-mapping hypermedia system. The following subsections explain
our approach.
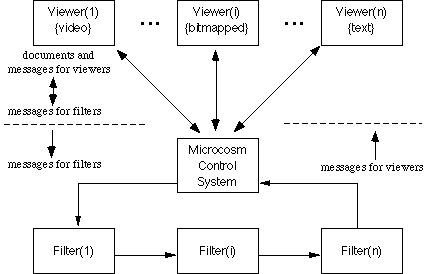
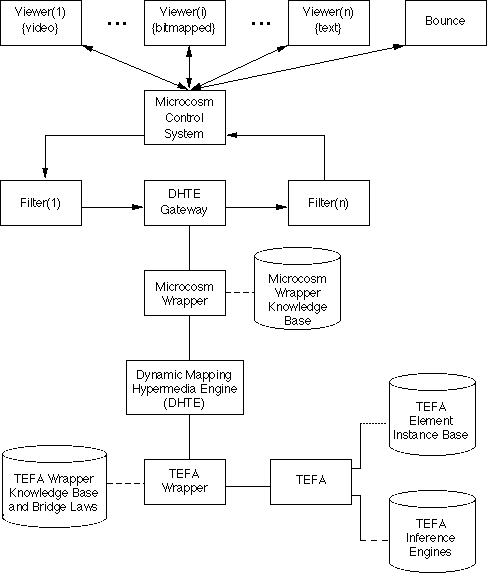
Figure 4 sketches Microcosm's architecture. Each viewer displays a particular medium. The Microcosm team has written "fully aware" viewers for media such as text, rtf (converted to formatted text), bitmapped graphics, object-oriented graphics, animation and video. In addition, they have developed macros for Microsoft Word, AutoCad and Visual Basic applications to function as "partially aware" viewers with a reduced set of Microcosm features, and as described in §2.3, to several other "unaware" viewers through their Universal Viewer mechanism [Davis et al. 1994].
The functional modules, called filters, each implement one aspect of Microcosm's functionality. Microcosm's standard filters include:
The DMIS, TEFA, is a model management system [Bhargava 1990] written in first-order predicate logic. TEFA declarations use the embedded languages approach [Bhargava 1995] in order to ensure maximum metainferencing power from within first-order logic, thereby ensuring robustness and logical completeness. TEFA has the following elements:
global_variable(result, 'Net
income after taxes').
local_var(result, net_income,
net, calculated, '$').
variable_quiddity(result,
currency, *, '$').
/* quiddity concerns
a variable's units and granularity [Bhargava 1995] */
global_variable(revenues,
'Gross receipts, i.e., money taken in').
local_var(revenues, net_income,
rev, given, '$').
variable_quiddity(revenues,
currency, *, '$').
global_variable(expenses,
'Expenditures').
local_var(expenses, net_income,
exp, given, '$').
variable_quiddity(expenses,
currency, *, '$').
global_variable(gross_profit,
'Revenues less expenses-net income before tax').
local_var(gross_profit,
net_income, gross, calculated, '$').
variable_quiddity(gross_profit,
currency, *, '$').
global_variable(tax_rate,
'Flat tax rate').
local_var(tax_rate, net_income,
tax, given, none).
variable_quiddity(tax_rate,
null, *, none).
equation(net_income, 1, net
=: gross * (1 - tax)).
equation(net_income, 2,
gross =: rev - exp).
assumes(net_income, 1, 'There
is a single flat tax rate used.').
assumes(net_income, 2, 'There
is a single pair of revenues and expenses').
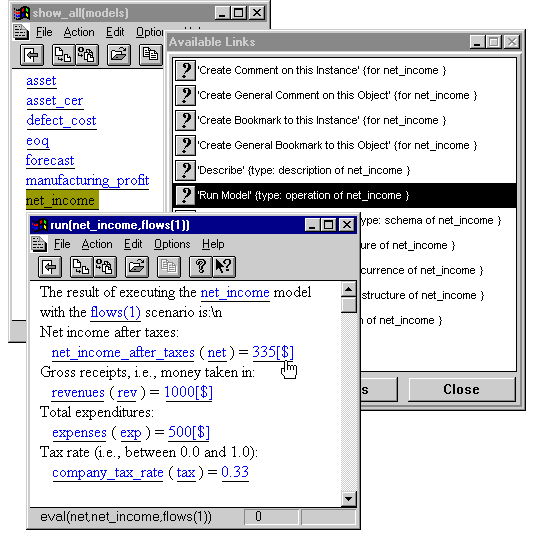
Table 1 presents a sample "net income" mathematical model in TEFA. Each TEFA element has several operations available. For example, for a mathematical model, the user can describe it, determine which data scenarios have data for executing it, execute it, list its submodels or list its local variables. For a local variable, the user can describe it and determine which models use it. TEFA's inference engines perform these operations and reasoning. Figures 6 and 7 show screen shots of this model. §3.5 presents the TEFA bridge laws declaring relationships inferable for it (or any other mathematical model instance in TEFA).
TEFA, as a DMIS, communicates with the DHTE entirely through messages generated by or received by the TEFA wrapper we wrote. TEFA stores all declared elements in the element instance base.
The DHTE converts TEFA messages into text documents, with the position of each link marker noted. TEFA messages consist of plain text, structured text (lists, tables, etc.) and marked-up TEFA components. The mark-up identifies which components have potential relationships and gives the display value and internal TEFA ID for each. TEFA's bridge laws, held in its wrapper's knowledge base, specify the component types, and the operations and other relationships available for each. We elaborate on these in the following subsection. TEFA's wrapper has the following routines:
The DHTE is event driven,
responding to user activity. Each DHTE module described below responds
to and/or produces a Microcosm message. Microcosm messages consist of an
arbitrary number of attribute/value pairs representing each message argument.
The "action" attribute/value pair represents the message type. The DHTE
passes an action parameter in its messages declaring menu items, anchors
and links. When the user selects one of these, Microcosm returns a message
with that action type. The DHTE includes the following modules. For each
we show the action attribute's value and relevant action parameters stored
with menu items, anchors and links for the Microcosm message that invokes
the module's functionality, and each message that DHTE returns in response.
We write standard Microcosm parameters in uppercase and specialized DHTE
parameters in lowercase [F4].
| message from | action value | actual action parameters |
| Microcosm (DCS) | SYSTEM.INFO | {none} |
| DHTE | {no direct response} |
| message from | action value | actual action parameters |
| Microcosm | {no direct call} | |
| DHTE | ADD.MENU.ITEM | dhte_menu_selected
(Owning_System, Command) |
| message from | action value | actual action parameters |
| Microcosm
(Viewer) |
dhte_menu_selected
(Owning_System, Command) |
{none} |
| DHTE | {no direct response} |
| message from | action value | actual action parameters |
| 1. Microcosm
(Viewer) |
a menu or
link selection
listed elsewhere |
{none} |
| 2. DHTE | IMPORT.DOCUMENT | {none} |
| message from | action value | actual action parameters |
| 3. Microcosm (DCS) | DOCUMENT.IMPORTED | {none} |
| 4. DHTE | AUTODISPATCH | {none} |
| message from | action value | actual action parameters |
| 5. Microcosm
(Viewer) |
FIND.BUTTONS | {none} |
| 6. DHTE | FOUND.BUTTON | dhte_button_id
(Component_Identifier); dhte_button_owner
|
| message from | action value | actual action parameters |
| Microcosm (DCS) | DISPATCH or AUTODISPATCH | {none} |
| DHTE | AUTODISPATCH | {none} |
| message from | action value | actual action parameters |
| Microcosm
(Viewer) |
FOLLOW.LINK | dhte_button_id
|
| DHTE | DISPATCH | dhte_link_command
|
| message from | action value | actual action parameters |
| Microcosm
(Bounce) |
dhte_link_action | dhte_link_command
|
| DHTE | {no direct response} |
We now describe DHTE and Microcosm's interaction with our example DMIS, TEFA.
[action, `MENU.ADD.ITEM`], [menuaction, `dhte_menu_selected(system('TEFA'),action(models))`], [menudescription, `TEFA\List All...\models`]
The format we use in this paper consists of a set of tag-value pairs, in which the first item is the "tag" and the second is the "value." Tag action is the message tag discussed in §3.4. Menuaction marks the command to be passed back if the user selects this menu. Menudescription marks the menu's label. Because Microcosm will only allow customized menu items under its flat "Action" menu, the wrapper simulates the menu hierarchy TEFA and DHTE assume by embedding the hierarchy within each menu item's label. Thus "TEFA\List All...\models" represents that the "models" menu item normally would be found under a "List All..." menu, which would be found under a "TEFA" menu.
2. Assume the user chooses TEFA's "list all models" command. The viewer (user interface) passes the following message to the filter chain:
[action, `dhte_menu_selected(system('TEFA'),action(models))`], [DoctName, `373.13.44.15.24.01.95.500`], [DoctType, `TEXT`], [Selection, ``], [Offset, 0]
DoctName marks Microcosm's identifier for the document at the time the user chose the menu. Selection contains any text highlighted in that document. Offset marks the starting character position of the selection or cursor. DHTE only uses the action in this case.
3. DHTE's Menu Selected module intercepts the message and passes the TEFA command "models" to TEFA.
4. TEFA executes the command and returns a document comprising a list of TEFA models.
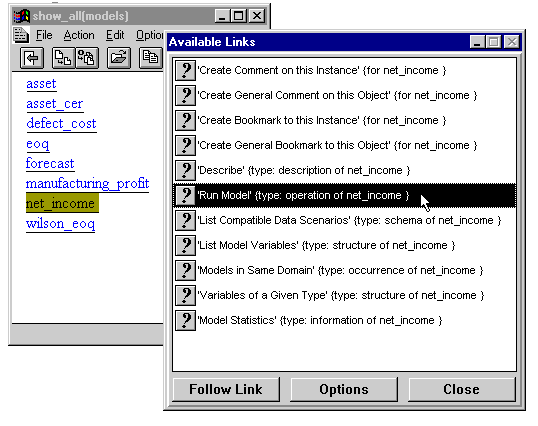
5. Because TEFA identifies each model as a separate object, the DHTE makes each an anchor ("button") in the document, which it then dispatches to Microcosm for display in the viewer. The Microcosm wrapper sends Microcosm the following type of message for each anchor. Note that the Microcosm wrapper includes several extra attributes which Microcosm passes back when the user selects this anchor. Figure 6 shows this document, entitled "show_all(models)" with the anchors highlighted. (Note that every piece of content is an anchor, as each is the name of a TEFA model.)
[action, `FOUND.BUTTON`], [DoctName, `373.13.44.15.24.01.95.701`], [DoctType, `TEXT`], [Selection, `net income`], [Offset, 73], [buttonaction, `FOLLOW.LINK`], [description, `model('net income')`], [dhte_button_id, `model('net income')`], [dhte_button_owner, `TEFA`]
6. When the user selects a model anchor, such as the net income model's, the viewer passes the following message to the filter chain:
[action, `FOLLOW.LINK`], [DoctName, `373.13.44.15.24.01.95.701`], [DoctType, `TEXT`], [Selection, ``], [Offset, 0], [dhte_button_id, `model('net income')`], [dhte_button_owner, `TEFA`]
7. DHTE's Anchor Selected module intercepts the message. It infers the existence of seven TEFA bridge laws for models. Figure 6 shows the resulting seven relationships, preceded by four DHTE commands available for this model. ([Bieber 1992, 1995] describe the parsing and bridge law mapping in more detail. Table 2 in §3.5 shows all TEFA bridge laws, including the element type, relation and meaning of each. We describe TEFA's bridge law relationships further in §3.5 below.) The Anchor Selected module sends each bridge law's link to Microcosm's Available Links filter in the following type of message:
[action, `DISPATCH`], [DoctName, `dummy`], [DoctType, `BOUNCE`], [bounceaction, `dhte_link_action`], [dhte_link_command, `run(net_income)`], [dhte_link_command_owner, `TEFA`], [description, `Run Model`]
8. Figure 6 shows Microcosm's resulting available links dialog. If the user selects, for example, the "run model" link, Microcosm's Available Links filter passes the prior message on to the Bounce module. Bounce exchanges the action attribute values as described above and forwards the message back into the filter chain.
9. DHTE's Link Selected module interprets the message and passes the TEFA command "run(net_income)" to TEFA.
|
|
|
|
|
| calculation result | operation | explain result | |
| calculation result | operation | convert units (quiddity) | |
| datum | information | list source | |
| datum | operation | convert units (quiddity) | |
| datum | operation | change value | |
| equation | description | describe equation | |
| equation | information | list equation assumptions | |
| equation | occurrence | show this equation in other models |
|
| function | information | describe function | |
| function | operation | execute this function | |
| global variable | information | describe variable | |
| global variable | occurrence | list data scenarios containing this variable |
|
| local variable | description | describe variable | |
| local variable | structural | list models using this variable | |
| model | description | describe model | |
| model | operation | execute (run) model | |
| model | schema | suggest data scenarios for model | |
| model | structural | list local variables within model | |
| model | schema | list models in the same application domain |
|
| model | structural | list variables in the model of a given quiddity |
|
| model | information | generate statistics about this model |
|
| relation | description | describe relation | |
| scenario | description | describe data scenario | |
| scenario | schema | list models that can use this data scenario | |
| scenario | information | generate statistics about this data scenario |
|
Following are some notes on the general relationships and bridge laws.
Operation Relationships
Because all the non-supplemental
bridge laws in Table 2 actually invoke existing TEFA commands, we could
have labeled each as an operation relationship. We have chosen, though,
to categorize many of them in terms of the other general relationships
types. Doing so pointed out to us several "under supported" general relationship
types. This prompted us to follow our own advice from §2.1. Using
the general relationship types to prime our thoughts, we (surprisingly
quickly) thought of many individual relationships that TEFA lacked, from
which we chose six to implement preliminarily. We have checked these six
in Table 2.
Schema Relationships
To demonstrate supplemental
schema relationships, we added an external set of application domains to
TEFA's wrapper and allow model builders to associate their models with
an application domain.
Process Relationships
TEFA does not provide process
support and we have not yet supplemented TEFA with any. We do, however,
envision bridge laws that declare step-by-step processes such as adding
new models or performing a complete analysis that considers an adequate
number of different data scenarios (i.e., adequate what-if analysis). We
leave this to future research.
Contingent Relationships
Through bridge laws, DHTE
can provide users with the other seven general relationships automatically.
In addition, hypermedia as a concept inherently includes uninferable contingent
or ad hoc relationships declared by users. For example, users could create:
---
The above items illustrate
our general relationship types for a mathematical modeling DMIS. Wan [1996]
describes some associative, operation, structural and metainformation relationships
for relational database management systems. Bieber and Kacmar [1995] describe
some useful relationships for geographic information systems. Bieber and
Vitali [1997] describe general relationships for a customer invoice system.
Although they do not classify them as such, Kimbrough and Vachula [1996]
provide a set of analogous schema, structural, information and occurrence
relationships for object oriented programming environments. This set would
make an excellent collection of supplemental bridge laws for that domain.
We note the limitation that
DHTE currently does not support (meta)relationships on other relationships,
such as annotating an occurrence relationship, or providing metainformation
on process relationships. The following subsection describes the compliance
DHTE demands of DMISs and UISs to support some of DHTE's other limitations.
In this subsection we describe
the compliance the DHTE demands from the UIS and the DMIS. This compliance,
together with the functionality described in §4 which we have not
yet implemented, constitute the limitations to our approach and to our
current prototype.
Currently builders must represent bridge laws in Prolog predicates. We hope to remove this restriction by accepting other formats, perhaps through a bridge law editor. (Wan [1996] and Wan and Bieber [1997] have declared templates for bridge laws, but these too require complex specifications.)
Each builder must develop his own set of bridge laws. We hope to develop bridge law libraries that map classes of information systems-complete "standard" bridge law sets that handle the models, attributes, data and operations found, e.g., in linear program (LP) packages, spreadsheet packages, or rule-based expert system shells. The builder of, say, a new LP package would only have to match the elements in his system to those in the standard LP set. The standard set would provide most of the bridge laws for his system. This would reduce the builder's effort both in determining which kinds of bridge laws would represent his system adequately and in developing these laws. Wan [1996] and Wan and Bieber [1997] have demonstrated this approach for relational database management systems.
---
Even if a DMIS has no bridge
laws and passes messages without objects, the hypermedia engine still will
provide standard hypermedia functionality (user annotation, backtracking,
etc.) In this case the user will not be able to access DMIS items or operations
in a hypermedia fashion through the DHTE.
The architecture we propose in this section could provide this environment. Figure 8 describes a distributed, multi-user, multi-application architecture at a high, conceptual level. All components may be distributed, including the DHTE and the Master Schema Knowledge Base (MSKB). The DHTE and MSKB can be replicated (have separate implementations) for independent groups of users.
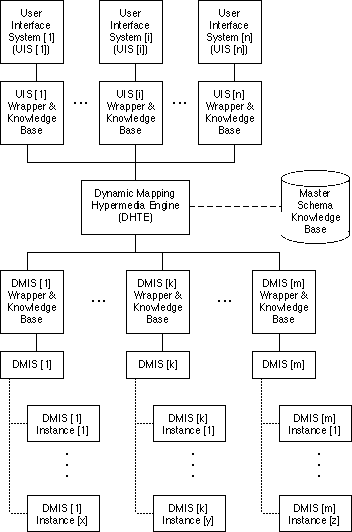
The MSKB plays a crucial role in this architecture. This knowledge base ties together the various DMISs in the system. We intend for it to contain meta-bridge laws which coordinate the bridge laws among DMISs. This will enable process support across applications [Tanik et al. 1996], occurrence relationships (locating and tracking a piece of data across applications) and schema relationships (e.g., finding the corresponding models or routines) across DMISs. Our tentative approach is to develop an application design coordination schema which will allow us to map standard design documents from different design methodologies (entity-relationship diagrams, data flow diagrams, OMT design diagrams, etc.) to each other. Kimbrough and Vachula [1996] provide a preliminary logic-based approach for object-oriented design methodologies, which we intend to expand for other methodologies.
Other hypermedia research
systems either support multiple users or multiple applications. Yet to
our knowledge, no other hypermedia engine besides OO-Navigator for Smalltalk
applications [Garrido and Rossi 1996] provides full hypermedia support
to computation-oriented (dynamic mapping) applications with minimal or
no alterations. The open hypermedia systems field has made progress towards
seamless integration, but has produced no standard way to support business
and engineering analysis applications requiring dynamic mapping.
We also could take advantage of this arrangement to achieve a division of labor. The OHS would provide all standard hypermedia navigation and linking features. We would provide all dynamic mapping and DMIS access. The integration would enable us to concentrate our future research efforts on dynamic mapping abilities and relationship management. The OHS community will continue to research integration issues, and continue to improve hypermedia structures, annotation and navigation features. Each of us would be able to take full advantage of the research successes of the other on an on-going basis.
We plan to make several improvements to our prototype. First, we intend to implement the full range of hypermedia functionality including sophisticated backtracking [Bieber and Wan 1994; Garzotto et al. 1996a], metarelationships on relationships, guided tours and overviews. Second, we plan to support process relationships [Bieber 1996; Bieber and Vitali 1997; Scacchi 1989; Noll and Scacchi 1996] much more fully, both for single applications and to support analysts working with multiple applications (as in §3.7). After this we intend to extend our hypermedia engine so it works with a DMIS' existing interface. In this case the UIS in Figures 3 and 8 would be the current interface of its DMIS. The engine would intercept the application's normal communications and insert hypermedia components into these messages [Bieber 1995]. In addition we plan to develop full guidelines for DMIS integration to expand those in §3.2. We also plan to implement the multi-user, multi-application architecture of §3.7 for DMIS applications, and to integrate our DHTE with existing OHS as described in §3.8. We also hope to investigate providing hypermedia support through hypermedia-unaware UISs, thereby complementing our approach to supporting DMISs. Finally, we note our firm commitment to demonstrating supplemental hypermedia support to other DMIS applications beyond model management and relational database management systems, etc. We would welcome collaboration with others in applying hypermedia to additional application areas such as CAD, computer-based training and education, CASE, EIS, expert systems, GIS, spreadsheets, and others.
At a larger scale we are witnessing the development of the new field of organizational hypermedia. Organizational hypermedia concerns the effects and implications of hypermedia as a concept and as a technology for supporting individuals and modern organizations. Organizational hypermedia [Isakowitz 1993] focuses on an organization's data and information management, as well as on managing collective knowledge [Marshall et al. 1995; Nanard and Nanard 1995b], organizational memory [Ackerman 1994; Croasdell et al. 1997; Tervonen et al. 1997] and decision support [Carlsson 1997; Chang et al. 1993; Mao et al. 1996]. Bieber and Isakowitz [1996] ask four fundamental questions for organizational hypermedia:
- How can we give users better
access to information?
- How can access to and
management of relationships enhance existing applications?
- How can one develop hypermedia-supported
applications?
- How might one evaluate
the effectiveness of hypermedia-assisted solutions?
While our work addresses aspects of the first three questions to a greater or lesser extent, to truly meet the challenge posed by the industrial strength vision of hypermedia support, much remains for investigation. First, we need more evidence of how hypermedia can support everyday users and their applications, in order to convince software developers to incorporate supplementary hypermedia support. Second, we need robust software engineering and systems analysis and design methodologies for developing hypermedia support. The methodologies mentioned in §2.3 constitute an excellent start. They support only certain types of applications and development from scratch. We need a design methodology for DMIS-style applications. We need design approaches for retrofitting supplementary hypermedia support to existing applications (including an organization's legacy systems [Bennett 1995]). We also should reiterate our belief from §2.1 that a hypermedia analysis can supplement other design methodologies. As part of our future research, we intend to develop a full hypermedia philosophy analysis methodology for non-hypermedia applications.
Regarding organizational hypermedia's fourth question, we note the paucity of metrics and evaluation approaches for hypermedia-supported applications [Brown 1990]. No self-respecting programmer or developer would release a commercial-quality product without thoroughly testing it first. Furthermore, in an effort to convince developers of hypermedia's usefulness, judging its effectiveness requires effective evaluation of hypermedia-supported systems. One can view evaluation in two ways. One can evaluate the actual node and link structure within an application (e.g., Do all links have endpoints? Can users get to the information they want within n link traversals?) One also can evaluate general accessibility or how well an application follows the hypermedia spirit or the "hypermedia feeling" [Vanharanta et al. 1995]: For every object visible on the screen, can the user easily gain access to all related information? Can the user clearly "see" how the information is related and under what context? Do the relationship and context remain clear once the user views the related information? Do the users of a hypermedia-enhanced system understand the system, its components and its results, and have confidence in these? A few researchers have started to work on hypermedia metrics [Botafogo et al. 1992; Garzotto et al. 1995; Rivlin et al. 1994; Vanharanta et al. 1995]. Commercial companies that provide hypermedia conversion and organizational support have developed robust sets of automatic evaluation tools (e.g., [Johnson 1995]) but these remain largely unpublished. Some researchers have done evaluation studies [Brown 1990; Minch and Green 1996; Vanharanta et al. 1995] but few actually advocate an evaluation methodology [Garzotto et al. 1995].
The hypermedia field contains
woefully little research and tools supporting analytical information systems.
Yet this is where we believe hypermedia will have its greatest impact,
especially for the scientific and business worlds. With the increased consciousness
of hypermedia which the World Wide Web has brought, developers and the
organizations for whom they work have never been more open to considering
their computer applications in a new light. Yet few guidelines exist for
assisting developers in providing access, i.e., in deciding what
to link, and few tools enable easy hypermedia integration for the vast
range of applications that dynamically generate information. And thus,
while hypermedia as a concept has made major contributions to the fields
of collaboration, technical communications and literature, and while both
outstanding research-oriented and commercially-available hypermedia environments
exist, the mainstream information systems development and software engineering
fields, for the most part, have not taken advantage of hypermedia concepts.
The time is ripe for an explosion in hypermedia support. We invite researchers
in all related fields to help guide the current intense interest to fruition.
I gratefully acknowledge
funding for this research by the NASA JOVE faculty fellowship program,
by the New Jersey Center for Multimedia Research, by the National Center
for Transportation and Industrial Productivity at the New Jersey Institute
of Technology (NJIT), by the New Jersey Department of Transportation, by
the New Jersey Commission of Science and Technology, as well as grants
from the Sloane Foundation and the AT&T Foundation, and the NJIT SBR
program.
AKSCYN, R., MCCRACKEN, D. AND YODER, E. KMS: a distributed hypermedia system for managing knowledge in organizations. Communications of the ACM 31(7) 1988, pages 820-835.
ANDERSON, K. Providing automatic support for extra-application functionality. In [Ashman et al. 1996], 1996.
ANDERSON, K. Integrating Open Hypermedia Systems with the World Wide Web. Hypertext'97 Proceedings, ACM Press, New York, NY, April 1997, 157-166.
ANDERSON, K., TAYLOR, R. AND WHITEHEAD, E. Chimera: hypertext for heterogeneous software environments. Proceedings of the Fifth ACM Conference on Hypermedia Technologies, Edinburgh, Scotland, September 1994, 94-107.
ASHMAN, H.L., BALASUBRAMANIAN, V., BIEBER, M. AND OINAS-KUKKONEN, H. (eds). Proceedings of the First International Workshop on Incorporating Hypertext Functionality Into Software Systems (HTF I), European Conference on Hypermedia Technologies (ECHT'94), Edinburgh, September 1994.
ASHMAN, H.L., BALASUBRAMANIAN, V., BIEBER, M. AND OINAS-KUKKONEN, H. (eds). Proceedings of the Second International Workshop on Incorporating Hypertext Functionality Into Software Systems (HTF II), Hypertext '96 Conference, Bethesda, March 1996.
ASHMAN, H.L., BALASUBRAMANIAN, V., BIEBER, M. AND OINAS-KUKKONEN, H. (eds). Proceedings of the Third International Workshop on Incorporating Hypertext Functionality Into Software Systems (HTF III), Hypertext '97 Conference, Southampton UK, April 1997.
BANKER, R., ISAKOWITZ, T., KAUFFMAN, R., KUMAR, R. AND ZWEIG, D. Tools for managing repository objects. Software engineering economics and declining budgets, Geriner, T., Gulledge, T. and Hutzler, W. (eds.), Springer Verlag, 1993, 125-146.
BAPAT, A., WÄSCH, J., ABERER, K. AND HAAKE, J. HyperStorM: an extensible object-oriented hypermedia engine. Hypertext'96 Proceedings, Washington, DC, March 1996, 203-214.
BENNETT, K. Legacy systems: coping with success. IEEE Software, January 1995, 19-23.
BHARGAVA, H. A logic model for model management. Ph. D. Dissertation, The Wharton School, University of Pennsylvania, Philadelphia, PA 19104, 1990.
BHARGAVA, H. Using quiddities for detecting semantic conflicts in information systems. Journal of Organizational Computing 5(4), 1995, 379-400.
BIEBER, M. Generalized hypertext in a knowledge-based DSS shell environment. Ph. D. Dissertation, The Wharton School, University of Pennsylvania, Philadelphia, PA 19104, 1990.
BIEBER, M. Automating hypermedia for decision support. Hypermedia 4, No. 2 (1992) 83-110.
BIEBER, M. On integrating hypermedia into decision support and other information systems. Decision Support Systems 14, 1995, 251-267.
BIEBER, M. Developing a freight data executive MIS for New Jersey using hypertext. Technical Report CIS96-9, New Jersey Institute of Technology, Computer and Information Sciences Department, 1996.
BIEBER, M. AND ISAKOWITZ, T. (eds.) Designing Hypermedia Applications. Special issue of the Communications of the ACM 38(8), 1995.
BIEBER, M. AND ISAKOWITZ, T. Introduction to the special issue: hypermedia in information systems and organizations. Journal of Organizational Computing and Electronic Commerce 6(3), 1996, iii-vii.
BIEBER, M., ISAKOWITZ, T. AND OLIVER, J. An analysis framework for information comprehension and access management. Proceedings of the Twenty-Eighth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1995), IEEE Press, Washington, D.C., Volume IV, pages 603-613.
BIEBER, M. AND KACMAR, C. Designing hypertext support for computational applications. Communications of the ACM 38(8), 1995, 99-107.
BIEBER, M. AND KIMBROUGH, S. On generalizing the concept of hypertext. Management Information Systems Quarterly 16(1), 1992, 77-93.
BIEBER, M. AND KIMBROUGH, S. On the logic of generalized hypertext. Decision Support Systems 11, 1994, 241-257.
BIEBER, M. and VITALI, F. (1997). Toward support for hypermedia on the World Wide Web. IEEE Computer 30(1), 1997, 62-70.
BIEBER, M., VITALI, F., ASHMAN, H., BALASUBRAMANIAN V., and OINAS-KUKKONEN, H. Fourth generation hypermedia: some missing links for the World Wide Web. forthcoming in the International Journal of Human Computer Studies.
BIEBER, M. AND WAN, J. Backtracking in a multi-window hypertext environment. European Conference on Hypermedia Technologies'94 Proceedings (Edinburgh, Scotland; September 1994), ACM Press, 158-166.
BOTAFOGO, R., RIVLIN, E. AND SHNEIDERMAN, B. Structural analysis of hypertext: identifying hierarchies and useful metrics. ACM Transactions on Information Systems 10(2), 1992, 142-180.
BROWN, P. Assessing the quality of hypertext documents. Hypertext: Concepts, Systems and Applications, Proceedings of ECHT'90, Versailles, France, November 1990, Rizk, A. Streitz, N. and André, J. (eds), Cambridge Press, pages 1-12.
BRUSILOVSKY, P., Methods and techniques of adaptive hypermedia. in User Modeling and User-Adapted Interaction 6, Kluwer, 1996, 87-129.
BUFORD, J. Evaluating HyTime: an examination and implementation experience. Hypertext'96 Proceedings, Washington, DC, ACM Press, March 1996, 105-115.
CALVI, L. AND DE BRA, P. Improving the usability of hypertext courseware through adaptive linking. Hypertext'97 Proceedings, ACM Press, New York, NY, April 1997, 224-225.
CAMPBELL, B. AND GOODMAN, J. HAM: a general purpose hypertext abstract machine. Communications of the ACM 31(7), 1988, 856-861.
CARLSSON, C. Fuzzy logic and hyperknowledge: a new effective paradigm for active DSS. Proceedings of the Thirtieth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1997), IEEE Press, Washington, D.C., Volume V, pages 324-333.
CARR, L., DE ROURE, D., HALL, W. AND HILL, G. The Distributed Link Service: a tool for publishers, authors and readers. Proceedings of the Web Revolution: Fourth International World Wide Web Conference, The Web Journal 1(1), O'Reilly and Associates, 1995.
CATLIN, T., BUSH, P. AND YANKELOVICH, N., InterNote: extending a hypermedia framework to support annotative collaboration. Hypertext '89 Conference, ACM Press, 1989, 365-378.
CHANG, A., HOLSAPPLE, C. AND WHINSTON, A. The hyperknowledge framework for decision support systems. Information Processing and Management, 1993.
CHIU, C.M. Fusing the World Wide Web and the open hypermedia system technologies. Ph. D. dissertation, Rutgers University, Newark NJ 07102, 1997.
CHIU, C. AND BIEBER, M. A generic dynamic-mapping wrapper for open hypertext system support of analytical applications. Hypertext'97 Proceedings, ACM Press, New York, NY, April 1997, 218-219.
CONKLIN, E. J. Hypertext: a survey and introduction. IEEE Computer 20(9), 1987, 17-41.
CROASDELL, D., PARADICE, D. AND COURTNEY, J. Using adaptive hypermedia to support organizational memory and learning. Proceedings of the Thirtieth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1997), IEEE Press, Washington, D.C., Volume II, 281-289.
DAVIS, H. (A) To embed or not to embed. Communications of the ACM. 38(8), 1995, pp 108-109.
DAVIS, H. (B) Data integrity problems in an open hypermedia link service. Ph.D. Dissertation, University of Southampton, UK, 1995.
DAVIS, H., HALL, W., I. HEATH, HILL, G. AND R. WILKINS. Towards an integrated information environment with open hypermedia systems. Proceedings of the ACM Conference on Hypertext (Milan, Nov. 1992) 181-190.
DAVIS, H., KNIGHT, S. AND HALL, W. Light hypermedia link services: a study of third party application integration. Proceedings of the Fifth ACM Conference on Hypermedia Technologies, Edinburgh, Scotland, 1994, 158-166.
DAVIS, H., LEWIS, A. AND RIZK, A. A draft proposal for a standard open hypermedia protocol. Proceedings of the Second Workshop on Open Hypermedia Systems, in [Wiil and Demeyer 1996].
DELISLE, N. AND SCHWARTZ, M. Neptune: a hypertext system for CAD applications. Proceedings of the 1986 ACM SIGMOD Conference, May 1986, pages 132-143.
DEROSE, S. Expanding the notion of links. Hypertext '89 Proceedings, Pittsburgh, PA, November 1989, 249-257.
DIAZ, A. AND ISAKOWITZ, T. RM Case: Computer-aided support for hypermedia design and development. in [Fraïssé et al. 1995], 3-16.
DIAZ, A., ISAKOWITZ, T., MAIORANA, V. AND GILABERT, G. RMC: a tool to design WWW applications. Proceedings of the Fourth International World Wide Web Conference, Boston, December 1995, http://www.w3.org/WWW4.
ENGELBART, D. Knowledge domain interoperability and an open hyperdocument system. Proceedings of the Conference on Computer-Supported Cooperative Work, ACM Press, New York, 1990,143-156.
FOUNTAIN, A., HALL, W., HEATH, I. AND DAVIS, H. MICROCOSM: An open model for hypermedia with dynamic linking. Proceedings of European Conference on Hypertext (ECHT) '90 (Cambridge University Press, Versailles, Nov. 1990) 298-311.
FRAïSSÉ, S., GARZOTTO, F., ISAKOWITZ, T., NANARD, J. AND NANARD, M. (eds.), International Workshop on Hypermedia Design'95 Proceedings, Montpellier (June 1-2, 1995).
GAMMA, E., HELM, R., JOHNSON, R. AND VLISSIDES, J. Design patterns: elements of reusable object-oriented software, Addison-Wesley, 1995.
GARRIDO, A. AND ROSSI, G. A framework for extending object-oriented applications with hypermedia functionality. The New Review of Hypermedia and Multimedia 2, 1996, 25-41.
GARZOTTO, F., MAINETTI, L. AND PAOLINI, P. Hypertext design, analysis, and evaluation issues. Communications of the ACM 38(8), August 1995, 74-86.
GARZOTTO, F., MAINETTI, L. AND PAOLINI, P. (A) Navigation patterns in hypermedia data bases. Journal of Organizational Computing and Electronic Commerce 6(3), 1996, 211-237.
GARZOTTO, F., MAINETTI, L. AND PAOLINI, P. (B) Information reuse in hypermedia applications. Hypertext'96 Proceedings, Washington, DC, ACM Press, March 1996, 93-104.
GARZOTTO, F., PAOLINI, P. AND SCHWABE, D. HDM - a model-based approach to hypertext application design. ACM Transactions on Information Systems 11, No. 1 (1993) 1-26.
GRØNBÆK, K., HEM, J., MADSEN, O. AND SLOTH, L. Cooperative hypermedia systems: a Dexter-based architecture. Communications of the ACM 37(2), 1994, 64-74.
GRØNBÆK, K. AND TRIGG, R. Design issues for a Dexter-based hypermedia system. Communications of the ACM 37(2), 1994, 40-49.
GRØNBÆK, K. AND WIIL, U. Towards a reference architecture for open hypermedia. Proceedings of the Third Workshop on Open Hypermedia Systems, in [Wiil 1997].
HALASZ, F. Reflections on NoteCards: seven issues for the next generation of hypermedia systems. Communications of the ACM 31(7), 1988, 836-855.
HALASZ, F. AND SCHWARTZ, M. The Dexter hypertext reference model. (edited by Grønbæk, K. and Trigg, R.), Communications of the ACM 37(2), 1994, 30-39.
HARDMAN, L., BULTERMAN, D. AND VAN ROSSUM, G. The Amsterdam hypermedia model: adding time and context to the Dexter model. Communications of the ACM 37(2), 1994, 50-62.
HILL, G. AND HALL, W. Extending the Microcosm model to a distributed environment. European Conference on Hypermedia Technologies'94 Proceedings (Edinburgh, Scotland; September 1994), ACM Press, 32-40.
HIRATA, K., HARA, Y., SHIBATA, N. AND HIRABAYASHI, F. Media-based navigation for hypermedia systems. Hypertext'93 Proceedings, Seattle, November 1993, 159-173.
HIRATA, K., HARA, Y., TAKANO, H., AND KAWASAKI, S., Content-oriented Integration in Hypermedia Systems. Hypertext'96 Proceedings. Washington, DC, March 1996, 11-21.
INTERNATIONAL STANDARDS ORGANIZATION IEC IS 10744 Hypermedia/time-based document structuring language (HyTime). August 1992.
ISAKOWITZ, T., Hypermedia in information systems and organizations: a research agenda. Proceedings of Twenty-Sixth Annual Hawaii International Conference on System Science (HICSS) (Maui, Jan. 1993), Volume III, 361-369.
ISAKOWITZ, T., KAMIS, A. AND KOUFARIS, M. Extending the capabilities of RMM: Russian dolls and hypertext. Proceedings of the Thirtieth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1997), IEEE Press, Washington, D.C., Volume VI, pages 177-186.
ISAKOWITZ, T. AND STOHR, E. Hypertext-based relationship management for DSS. New York University Information Systems Department Working Paper IS-92-22 (New York, NY 10012, July 1992).
ISAKOWITZ, T., STOHR, E. AND BALASUBRAMANIAN, P. RMM: A methodology for structuring hypermedia design. Communications of the ACM 38(8), August 1995, 34-44.
KACMAR, C., Supporting hypermedia services in the user interface. Hypermedia 5(2), 1993, 85-101.
KACMAR, C. A process approach for providing hypermedia services to existing, non-hypermedia applications. Electronic Publishing: Organization, Dissemination, and Distribution 8(1), March 1995, 31-48.
KACMAR, C. AND LEGGETT, J. PROXHY: a process-oriented extensible hypertext architecture. ACM Transactions on Information Systems 9, No. 4 (1991) 399-419.
KIMBROUGH, S. On the reduction of genetics to molecular biology. Philosophy of Science 46(3), 1979, 389-406.
KIMBROUGH, S., PRITCHETT, C., BIEBER, M. AND BHARGAVA, H. The Coast Guard's KSS project. Interfaces 20, No. 6 (1990) 5-16.
KIMBROUGH, S. AND VACHULA, W. A propædeutic on logic for object-oriented systems analysis and design. Proceedings of the Twenty-Ninth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1996), IEEE Press, Washington, D.C., Volume II, 20-29.
JOHNSON, S. Quality control for hypertext construction. Communications of the ACM 38(8), 1995, 87.
LANDOW, G. Popular fallacies about hypertext. in Jonassen, D. and Mandl, H. (eds.) Designing hypermedia for learning, Series F. Computer and Systems Sciences 67, Springer-Verlag, 1990, 39-59.
LANGE, D. Object-Oriented Hypermodeling of Hypertext Supported Information Systems. Journal of Organizational Computing and Electronic Commerce 6(3), 1996, 269-293.
LEE, Y. K., YOO, S-J., YOON, K. AND BERRA, P. Querying structured hyperdocuments. Proceedings of the Twenty-Ninth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1996), IEEE Press, Washington, D.C., Volume II, pages 155-164.
LEGGETT, J. AND SCHNASE, J. Viewing Dexter with open eyes. Communications of the ACM 37(2), 1994, 77-86.
LEWIS, A. DAVIS, H., GRIFFITHS, S., HALL, W. AND WILKINS, R. Media-based navigation with generic links. Hypertext '96 Proceedings, ACM Press, 1996, 215-223.
LITTLEFORD, A. Artificial intelligence and hypermedia. in: Berk, E. and Devlin, J. (eds.) Hypertext/Hypermedia Handbook (Intertext Publications/McGraw-Hill Publishing Co., Inc., New York, 1991), 357-378.
LUCARELLA, D. AND ZANZI, A. A visual retrieval environment for hypermedia information systems. ACM Transactions on Information Systems 14(1), 3-29.
MAIOLI, C., PENZO, W., SOLA, S. AND VITALI, F. Using a reference model for information system compatibility: an experience. Proceedings of the Twenty-Seventh Hawaii International Conference on System Sciences, January 1994, Maui, Hawaii, Volume III, 376-385.
MAIOLI, C., SOLA, S. AND VITALI, F. Wide-area distribution issues in hypertext systems. ACM SIGDOC'93 Conference Proceedings, ACM Press, New York, 1993.
MALCOLM. K., POLTROCK, S. AND SCHULER, D. Industrial strength hypermedia: requirements for a large engineering enterprise. Hypertext `91 Proceedings, December 1991, 13-24.
MAO, J., BENBASAT , I. AND DHALIWAL, J. Enhancing explanations in knowledge-based systems with hypertext. Journal of Organizational Computing and Electronic Commerce 6(3), 1996, 211-237.
MARSHALL, C. AND SHIPMAN III, F. Spatial hypertext: designing for change. Communications of the ACM 38(8), 1995, 88-97.
MARSHALL, C., SHIPMAN III, F. AND COOMBS, J. VIKI: spatial hypertext supporting emergent structure. European Conference on Hypermedia Technologies'94 Proceedings (Edinburgh, Scotland; September 1994), ACM Press, 13-23.
MARSHALL, C., SHIPMAN III, F. AND MCCALL, R. Making large-scale information resources serve communities practice. Journal of Management Information Systems 11(4), 1995, 65-86.
MARSHALL, C. AND IRISH, P. Guided tours and on-line presentations: how authors make existing hypertext intelligible for readers. Hypertext '89 Proceedings (Pittsburgh, Nov. 1989) 15-42.
MEYROWITZ, N. The missing link: why we're all doing hypertext wrong. in The society of text: hypertext, hypermedia, and the social construction of information, Barrett, E. (ed.), MIT Press, Cambridge, MA, 1989, 107-114.
MINCH, R. AND GREEN, G. An investigation of hypermedia support for problem decomposition. Journal of Organizational Computing and Electronic Commerce 6(3), 1996, 295-323.
NANARD, J. AND NANARD, M. (A) Hypertext design environments and the hypertext design process. Communications of the ACM 38(8), 1995, 49-56.
NANARD, J. AND NANARD, M. (B) Adding macroscopic semantics to anchors in knowledge-based hypertext. International Journal of Human-Computer Studies 43, 1995, 363-382.
NEWCOMB, S., KIPP, N. AND NEWCOMB, V. The 'HyTime' hypermedia/time-based document structuring language. Communications of the ACM 34(11), 1991, 67-83.
NIELSEN, J. The art of navigating through hypertext. Communications of the ACM 33(3), March 1990, 296-310.
NIELSEN, J. Multimedia and hypertext: the Internet and beyond. AP Professional, 1995.
NOLL, J. AND SCACCHI, W. Repository support for the virtual software enterprise. In [Ashman et al. 1996].
OINAS-KUKKONEN, H. Debate Browser - an argumentation tool for MetaEdit+ Environment. Proceedings of the Seventh European Workshop on Next Generation of CASE Tools (NGCT '96), Crete, Greece, 1996, 77-86.
OINAS-KUKKONEN, H. Embedding hypermedia into information systems. Proceedings of Thirtieth Annual Hawaii International Conference on System Science, IEEE Computer Society Press, Los Alamitos, 1997, Volume VI 187-196.
ØSTERBYE, K. AND WIIL, U. The Flag Taxonomy of open hypermedia systems. Hypertext'96 Proceedings, ACM Press, New York, 1996, 129-139.
PARUNAK, H. (A) Ordering the information graph. in Hypertext/hypermedia handbook, Berk, Emily and Joseph Devlin (eds.), Intertext Publications/McGraw-Hill Publishing Co., Inc., New York, 1991, 299-325.
PARUNAK, H. (B) Toward Industrial Strength Hypermedia. in Hypertext/hypermedia handbook, Berk, Emily and Joseph Devlin (eds.), Intertext Publications/McGraw-Hill Publishing Co., Inc., New York, 1991, 381-395.
PEARL, A. Sun's Link Service: a protocol for open linking. Hypertext '89 Proceedings (Pittsburgh, Nov. 1989) 137-146.
PUTTRESS, J. AND GUIMARAES, N. The toolkit approach to hypermedia. Hypertext: Concepts, Systems and Applications, Proceedings of ECHT'90, Versailles, November 1990, Rizk, A., Streitz, N. and André, J. (eds.), Cambridge University Press, 25-37.
RANA, A. AND BIEBER, M. Towards a collaborative hypermedia education framework. Proceedings of Thirtieth Annual Hawaii International Conference on System Science (HICSS) (Maui, Jan. 1997), II 610-619.
RAO, U. AND TUROFF, M., Hypertext functionality: a theoretical framework. International Journal of Human-Computer Interaction 2(4), 1990, 333-358.
RIZK, A. AND SAUTER, L. Multicard: an open hypermedia system. Proceedings of the ACM Conference on Hypertext (Milan, Nov. 1992) 4-10.
RIVLIN, E., BOTAFOGO, R. AND SHNEIDERMAN, B. Navigating in hyperspace: designing a structure-based toolbox. Communications of the ACM 37(2), 1994, 87-108.
ROSSI, G., GARRIDO, A. AND CARVALHO, S. Design patterns for object-oriented hypermedia applications. In: Pattern languages of programs II. Vlissides, J., Coplien, J. and Kerth, N. (eds.) Addison-Wesley, 1996, pp. 177-191.
ROSSI, G., SCHWABE, D. AND GARRIDO, A. Design reuse in hypermedia application development. Hypertext'97 Proceedings, ACM Press, New York, 1997, 57-66.
SCACCHI, W. On the power of domain-specific hypertext environments. Journal of the American Society for Information Science 40(3), 1989, pages 183-191.
SHERMAN, M., HANSEN, W., MCINERNY, M., AND NEUENDORFER, T. Building hypertext on a multimedia toolkit: an overview of the Andrew toolkit hypermedia facilities. Proceedings of European Conference on Hypertext (ECHT) '90 (Cambridge University Press, Versailles, Nov. 1990) 13-24.
SCHÜTT, H. AND STREITZ, N., HyperBase: a hypermedia engine based on a relational database management system. In: Rizk, A., Streitz, N. and André, J. (eds.) Hypertext: Concepts, Systems and Applications, Proceedings of ECHT'90, Versailles, November 1990. Cambridge: Cambridge University Press, 95-108.
SCHWABE, D., ROSSI, G. AND BARBOSA. S. Systematic hypermedia application design with OOHDM. Hypertext'96 Proceedings, March 16-20, 1996, 116-128.
STOTTS, P. D. AND FURUTA, R. Petri-net-based hypertext: document structure with browsing semantics. ACM Transactions on Information Systems 7(1), 1989. 3-29.
TANIK, M., YEH, R., BIEBER, M., KURFESS, F., LIU, Q., MCHUGH, J., RANA, A., ROSSAK, W. AND NG, P. Issues and architecture for electronic enterprise engineering (EEE). Proceedings of the Second World Conference on Integrated Design and Process Technology, Society for Design and Process Science, (Austin, Dec. 1996), Volume 2, 57-62. [http://www.cs.njit.edu/~eee/pubs/sdps96.html]
TERVONEN, I., KEROLA, P. AND OINAS-KUKKONEN, H. An organizational memory for quality-based software design and inspection: a collaborative multiview approach with hyperlinking capabilities. Proceedings of the Thirtieth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1997), IEEE Press, Washington, D.C., Volume II, 290-299.
THÜRING, M., HANNEMANN, J. AND HAAKE, J. Hypermedia and cognition: designing for comprehension. Communications of the ACM 38(8), 1995, 57-69.
TRIGG, R. AND WEISER, M. TextNet: A network-based approach to text handling. ACM Transactions on Office Information Systems 4, No. 1 (1986) 1-23.
UTTING, K. AND YANKELOVICH, N. Context and orientation in hypermedia networks. ACM Transactions on Information Systems 7, No. 1 (1989) 58-84.
VANHARANTA, H., KÄKÖLÄ, T. AND BACK, B. Validity and utility of a hyperknowledge-based financial benchmarking system. Proceedings of the Twenty-Eighth Hawaii International Conference on System Sciences, January 1995, Maui, Hawaii, Volume III, 221-230.
WAN, J. Integrating hypertext into information systems through dynamic linking. Ph. D. dissertation, New Jersey Institute of Technology, Institute for Integrated Systems Research, Newark NJ 07102, 1996.
WAN, J. AND BIEBER, M. GHMI: a general hypertext data model supporting integration of hypertext and information systems. Proceedings of the Twenty-Ninth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1996), IEEE Press, Washington, D.C., Volume II, pages 47-56.
WAN, J. AND BIEBER, M. Providing relational database management systems with hypertext. Proceedings of the Thirtieth Annual Hawaii International Conference on System Sciences (Wailea, Maui; January 1997), IEEE Press, Washington, D.C., Volume VI, 160-166.
WANG, W. AND RADA, R. experiences with semantic net based hypermedia. International Journal of Human-Computer Studies, 43, 419-439, 1995.
WHITEHEAD, E. J. An architectural model for application integration in open hypermedia environments. Hypertext'97 Proceedings, ACM Press, New York, 1997, 1-12.
WIIL, U. (ed.). Proceedings of the 3rd Workshop on Open Hypermedia Systems. CIT Scientific Report #SR-97-01, 1997, The Danish National Centre for IT Research, Forskerparken, Gustav Wieds Vej 10, 8000 Aarhus C, Denmark [on-line] http://www.cit.dk/
WIIL, U. AND DEMEYER, S. (eds). Proceedings of the 2nd Workshop on Open Hypermedia Systems. at Hypertext'96, Washington, March 16-17, 1996. UCI-ICS Technical Report 96-10, Department of Information and Computer Science, University of California, Irvine, CA 92717-3425.
WIIL, U. AND LEGGETT, J. The HyperDisco approach to open hypermedia systems. Hypertext'96 Proceedings, ACM Press, New York, 1996, 140-148.