- Configure and run a stable release of Apache Hadoop in the pseudo-distributed mode.
- Develop a MapReduce-based approach in your Hadoop system to compute the relative frequencies of each word that occurs in all the documents in 100KWikiText.txt, and output the top 100 word pairs sorted in a decreasing order of relative frequency. The relative frequency (RF) of word B given word A is defined as follows:
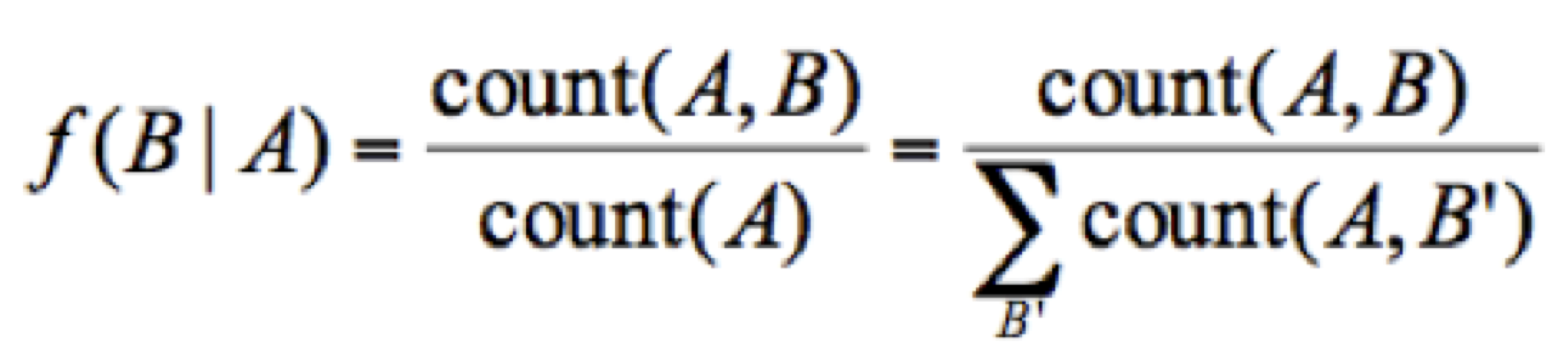
where count(A,B) is the number of times A and B co-occur in the entire document collection, and count(A) is the number of times A occurs with anything else. Intuitively, given a document collection, the relative frequency captures the proportion of time the word B appears in the same document as A.
Note: It is not very meaningful to consider a word (A) that only appears once in the entire document. Hence, you need to first rank all words according to their use frequencies (using WordCount) and then consider only top 100 words for the RF calculation of their pairs.
- Repeat the above steps using at least 2 VM instances in your Hadoop system running in the fully-distributed mode.
Submission requirements: A zipped file that contains