| Physics 728 |
Radio Astronomy: Lecture #6
|
Prof. Dale E. Gary
NJIT
|
Fourier Synthesis Imaging
Interferometer Response
to Plane Waves
The basic unit of
an interferometer array is the single baseline between two antennas, as
shown in Figure 1, below. A plane wave incident from directly overhead
will arrive at the antennas in phase, and if the signal travels the same
distance through cables to the correlator (shown with an X in the figure,
because it is just a multiplication), the signal from the two antennas
will give a maximum response.
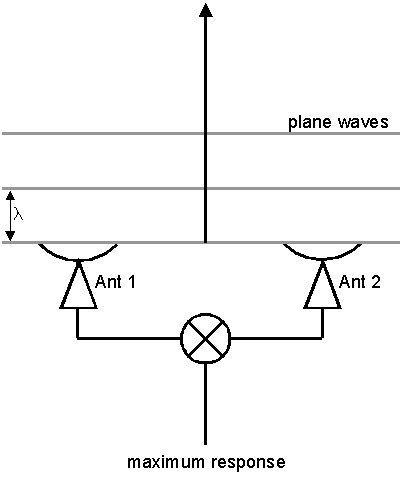
Figure 1: Geometry
of an interferometer baseline, with plane
waves incident vertically,
of wavelength λ.
If the plane wave comes from
a slightly different direction, it will arrive at the antennas slightly
out of phase, and the response will be less, except that when the waves
arise exactly 1 wavelength out of phase the response will again be a maximum,
as shown in Figure 2.
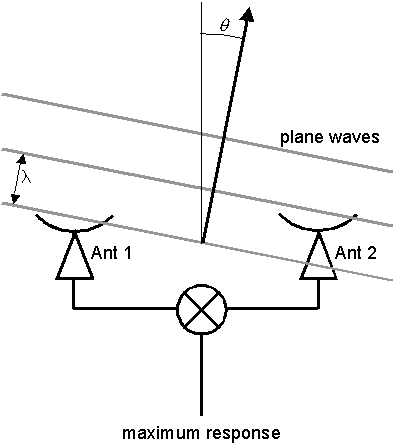
Figure 2: The same
baseline as in FIgure 1, but for waves incident from
an angle θ
from the vertical. The waves arrive at the antennas again
exactly in phase, because
the angle is such that the difference in path length is λ.
The angle for which the secondary
maximum occurs is
θ = sin−1λ/B
(1)
where B
is the baseline length, or distance between antennas. The angle θ
is also called the fringe spacing, as introduced in Lecture 4. Additional
maxima occur at integer multiples of θ,
to provide the fringe pattern across the sky. Recall from Lecture
4 that in two dimensions the fringe pattern looks like the left panel of
the figure below.
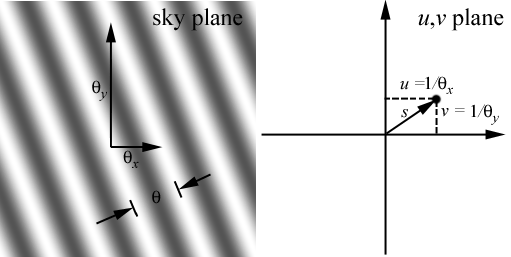
If we have a truly monochromatic
system, the fringes will extend all the way across the sky with the same
amplitude. However, in practice our observation will be done over
some bandwidth Δν.
Since the spacing between fringes depends on wavelength, frequencies in
one part of the band will have fringes with one spacing, and fringes in
another part of the band will have another spacing, so that at large angles
the frequencies start interfering with each other. At what value
of θ
will there be an extra pathlength equal to one wavelength (i.e. nλ
at one end of the band, and (n+1)λ'
at the other end)? For homework you will show that this occurs at
θ = sin−1
(c/BΔν)
From this result, for Δν =
50 MHz we have θ=
0.82o.
So it is obvious that it is not possible to observe sources from anywhere
except in a narrow range of angles directly overhead without addressing
this problem of destructive interference across the band. The solution
is to insert a delay, τ,
in the signal path of one of the antennas to "steer" the phase
center as shown in Figure 3. When this is done, the
fringe spacing can be measured relative to this phase center direction
rather than from directly overhead.
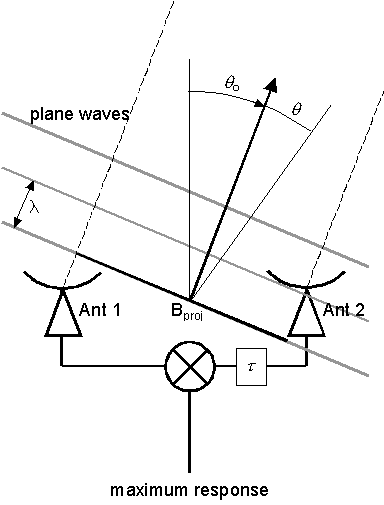
Figure 3: Geometry
of an interferometer baseline where a delay τ
is
inserted in one antenna,
in order to steer the phase center to a
direction θo
from the vertical λ.
However, our expression (1)
requires modification, since now it is the projected distance between antennas
that matters, not the distance along the ground. The fringe spacing
is now given by
θ = sin−1λ/Bproj
~ λ/Bproj
(2)
where we make the approximation
that θ
is small and is expressed in radians. Note that θ
is now measured relative to the phase center direction, θo.
The delay required to steer the phase center to the direction θo
is called the tracking delay,
and must be continually updated to track the source across the sky.
The signal we have been discussing,
with a maximum response at the phase center, is called the cosine
component of the signal. It is also possible to apply a phase shift
of π/2 to the signal from one of the antennas and measure this new signal,
called the sine component. These two components are measured
simultaneously. Using the notation
x = cosine
component
y = sine component
we can determine the amplitude
of the wavefront as
a = (x2
+ y2)1/2
and the phase of the wavefront
as
φ = tan−1
(y/x) .
Interferometer
Response in Terms of Sources
Point Source
Consider a point source
in the sky, of amplitude a1,
located an angular distance θ1
= 10 arcsec from the phase center, as shown
in Figure 4a. When measured
with a baseline whose fringe spacing is θ
= 30 arcsec, the phase φ1
of this source will be φ1
= 2πθ1
/θ = 2π/3,
which is the angle shown in Figure 4b.
The interferometer will measure a cosine component of x =
a1
cos(2π/3) = −a1/2,
and a sine component of y = a1
sin(2π/3) = 31/2a1/2.
These are the components of the vector shown in the phasor representation
of Figure 4b, and can be written
more compactly as
a1 exp(iφ1)
= a1 exp(i2πθ1
/θ) .
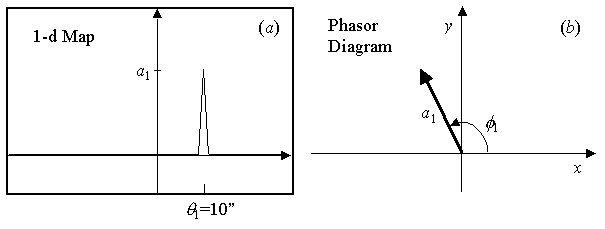
Figure 4: a)
The spatial map of a point source of amplitude a1
at spatial coordinate θ1.
b) The corresponding
phasor diagram showing the interferometer response in terms of
the amplitude a1
and phaseφ1.
Two Point Sources
Now consider what happens
when we add a second point source of amplitude a2,
located an angular distance θ2
= −2 arcsec from
the phase center. This is equivalent to adding another vector to
the phasor diagram, with phase φ2
= 2πθ2
/θ = −2π/15,
as shown in Figure 5. Note that now the response of the interferometer
is the vector sum of these two vectors,
with resultant
ar exp(iφr)
= a1 exp(i2πθ1
/θ) + a2exp(i2πθ2
/θ),
(3)
so the cosine and sine components
are x = ar cos(φr),
and y = ar sin(φr),
respectively.
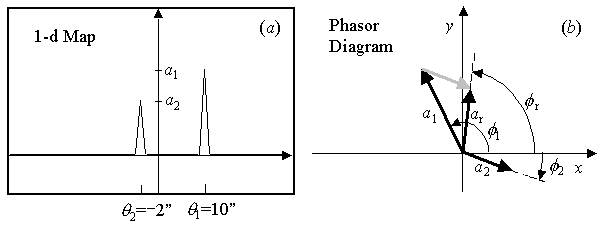
Figure 5: a)
The spatial map of two point sources of amplitudes a1
and a2
at spatial coordinate
θ1=10"
and θ2=−2".
b)
The corresponding phasor diagram showing the interferometer response
for the two sources, where
the resultant of amplitude ar
and phaseφr
is the vector sum of the two
individual responses.
A Continuous Distribution
of Brightness
Any continuous distribution
of brightness can be thought of as a collection of point sources.
Consider a source of gaussian cross-section,
a(θi)
= A exp(−[(θi−θo/α]2)
,
(4)
where the θi
are the discrete spatial coordinates of size, say, Δθ = θi −θi−1=
1". Figure 6 shows the spatial distribution
of equation (4) for a 1/e width
α = 5", centered at spatial coordinate θo = 10".
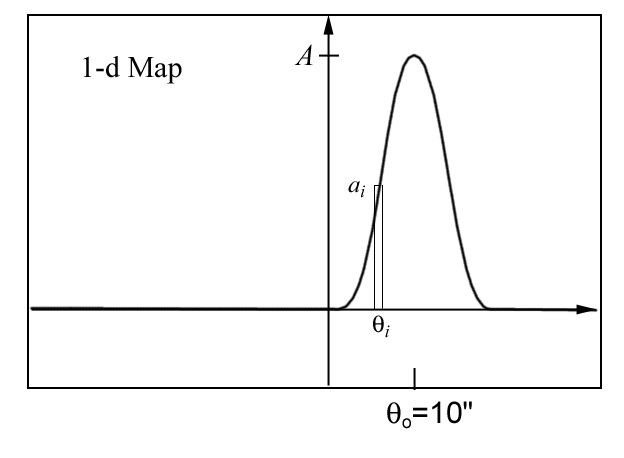
Figure 6: The spatial
map of the gaussian function shown in eq. (4). The amplitude and
position of one of the discrete
1" bins is shown.
By analogy with equation
(3), it is obvious that the resultant signal measured by an interferometer
baseline of fringe spacing θ,
will be
ar exp(iφr)
= Σiaiexp(i2πθi
/θ),
(5)
where the summation is over
the discrete 1" spatial bins. However, recall from Lecture 4 that
the fringe spacing is the inverse of the spatial frequency, i.e. θ =
1/s, and we identified coordinates
u
and v with the components of
s,
and the coordinates l and m
with the sky components of angular position θi.
Using these variables, equation (5) becomes
ar exp(iφr)
= Σiaiexp[i2π(ul
+ vm)].
(6)
The Complex Visibility
and Fourier Transform Relation
Finally, we define the response
of the interferometer as the complex visibility,
V(u,v)
= arexp(iφr),
define the sky brightness distribution as I(l,m) =
ai,
and make the obvious generalization from a discrete summation to a continuous
integral to obtain:
|
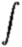 |
|
|
|
| V(u,v) = |
I(l,m) exp[−i2πul
+ vm)] |
dl |
dm .
(7) |
|
|
|
|
Equation (7) demonstrates
the Fourier Transform relationship between the sky brightness distribution
I(l,m)
and the interferometer response (complex visibility) V(u,v).
In particular, if we measure the interferometer response V(u,v),
we can invert it (inverse Fourier Transform) to obtain the sky brightness
distribution (the map):
|
|
|
|
|
| I(l,m) = |
V(u,v) exp[i2πul
+ vm)] |
du |
dv .
(8) |
|
|
|
|
Obtaining u,v
From An Antenna Array
A synthesis imaging
radio instrument consists of a number of radio elements (radio dishes,
dipoles, or other collectors of radio emission), which represent measurement
points in u,v space. We
now need to describe how to convert an array of dishes on the ground to
a set of points in u,v space.
E, N, U coordinates to
x, y, z
The first step is to determine
a consistent coordinate system. Antennas are typically measured in
units such as meters along the ground. We will use a right-handed
coordinate system of East, North, and Up (E, N, U).
These coordinates are relative to the local horizon, however, and will
change depending on where we are on the spherical Earth. It is convenient
in astronomy to use a coordinate system aligned with the Earth's rotational
axis, for which we will use coordinates x, y, z
as shown in Figure 7. Conversion from (E, N, U)
to (x, y, z) is done via a simple
rotation matrix:
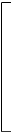 |
x
|
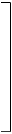 |
|
|
|
0
|
|
−sin λ
|
|
cos λ |
|
E |
|
|
y
|
|
= |
1
|
|
0
|
|
0
|
N |
|
z
|
|
|
0
|
|
cos λ
|
|
sin λ
|
U |
which yields the relations
x = −N
sin λ + U cos λ
y = E
z = N cos λ
+ U sin λ
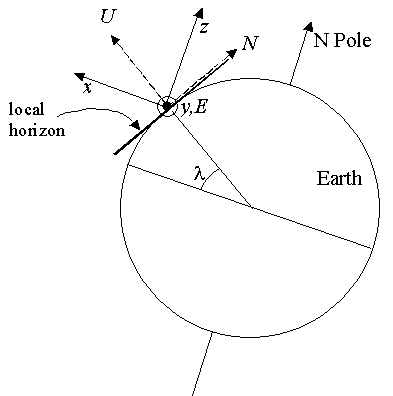
Figure 7: The relationship
between E, N, U
coordinates and x, y, z
coordinates,
for a latitude λ.
The direction of z
is parallel to the direction to the celestial pole.
The directions y
and E are
the same direction.
Baselines and Spatial Frequencies
Note that the baselines
are differences of coordinates, i.e. for the baseline between two antennas
we have a vector
B = (Bx,
By, Bz)
= (x2−x1,
y2− y1,
z2− z1).
This vector difference in positions
can point in any direction in space, but the part of the baseline that
matters in calculating u,v is
the component perpendicular to the direction θo
(the phase center direction), which we called Bproj
in Figure 3. Let us express the phase center direction as a unit
vector so = (ho,
δo),
where ho
is the hour angle (relative to the local meridian) and δo
is the declination (relative to the celestial equator). Then Bproj=
B.
so=
B
cos
θo.
Recall from Lecture 4 that
the spatial frequencies u,v
are just the distances expressed in wavelength units, so we can get the
u,v
coordinates from the baseline length expressed in wavelength units from
the following coordinate transformation:
|
u
|
|
|
1 |
|
sin ho
|
cos ho
|
|
0
|
|
Bx |
|
|
v
|
=
|
|
−sin δo
cos
ho
|
sin δo
sin
ho
|
|
cos δo
|
By |
|
w
|
|
λ
|
cos δo
cos
ho
|
−cos δo
sin
ho
|
|
sin δo
|
Bz |
Notice that we have introduced
a spatial frequency w, which
we must include to be accurate. However, if we limit our image to
a small area of sky near the phase center (small angular coordinates l,
m), then we can get away with considering
only u,v coordinates.
Ignoring w causes distortion that is akin to projecting a section of
the sky dome on a flat plane, as shown in Figure 8. The condition for
this to be valid is 1/2 (l2
+ m2)w << 1.
For w = 1000 wavelengths for
example, we could map out to about 1/30 radian or a little over 1 degree.
As we use higher frequencies and/or longer baselines, the part of the sky
we can map without distortion gets smaller. We will henceforth ignore
the w coordinate and assume
that we are measuring the sky in a small region near the phase center.
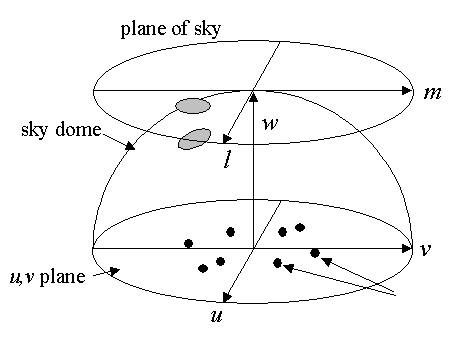
Figure 8: The sky
dome and its approximation as a flat "plane of the sky" are shown.
For baselines with a significant
w
component, the approximation of a flat sky causes
distortions near the edges
of the map. The gray oval on the plane of the sky is really
on the curved sky dome.
Note that u,v
depend on the hour angle, so as the Earth rotates and the source appears
to move across the sky, the array samples different u,v
at different times. Figure 9 shows an example with antenna locations
(9a), the corresponding u,v
points at a single instant in time (9b),
and the u,v points over many
hours in time (9c). The
u,v
points trace out portions of ellipses, called u,v tracks, and sample more
of the u,v plane. Making
a map over a long period of time is called Earth
Rotation Synthesis.
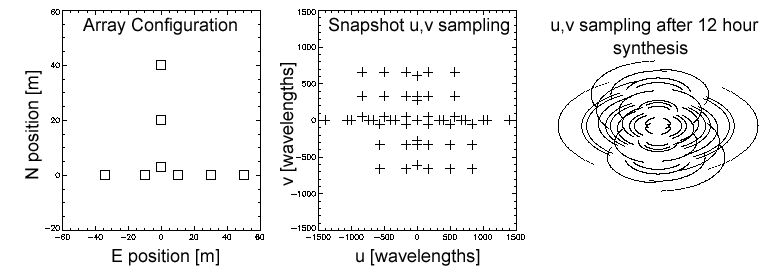
Figure 9: a)
An example array configuration consisting of 8 antennas, with E and N antenna
locations in meters.
b) The u,v sampling
that results from this array for a single time (snapshot), at zero hour
angle. Each cross represents
a baseline. There
are N(N-1)/2 = 28 unique baselines, but there are twice this many points
due to symmetry.
c) The u,v sampling
that results after a 12 hour integration. The rotating Earth causes
the projected baselines
to change with time, tracing
out portions of elliptical paths.
Sampling the Visibilities
The way to think
about the problem is to consider that for every sky brightness distribution
I(l,m)
there exists a visibility function V(u,v)
that is its Fourier Transform. This visibility function is everywhere
a continuous complex function. An array of antennas with baselines
Bλ,proj
= (ui,vi)
measures only certain values in the set of continuous (u,v)
in the visibility function. This measured set we call the sampling function S(u,v)
= Σkδ(u
−
uk,v
<−
vk).
Here δ(x,y)
is the 2-d delta function, and the sum is taken over all baselines.
The sampled visibility function S(u,v)V(u,v)
is the actual data provided by the array, and by performing the inverse
Fourier Transform we recover the "dirty image" ID(l,m),
given by
|
|
|
|
|
| ID(l,m)
= |
S(u,v)V(u,v) exp[i2πul
+ vm)] |
du |
dv .
(9) |
|
|
|
|
Note that the dirty image
uses only the sampled visibilities, and so does not contain full information
about the sky brightness distribution. We must use some image reconstruction
technique to recover the missing spacings. Note also that the actual
visibility function measured by the instrument is V'(u,v)
= V(u,v) + N(u,v), where
N(u,v)
is an unavoidable noise component.
We could use a "brute force"
method and calculate the dirty image via the direct Fourier Transform,
but this would require 2MN 2
multiplications, where M is
the number of samples (baselines*times, or u,v
points) and N is the linear
dimension of the image, in pixels. In practice, M ~ N
(to fill the u,v plane), so
multiplications (and sin/cos evaluations) go as N 4.
Instead, we use the
FFT, which requires of order (N 2
log2 N)
operations, but to use this requires gridding
the u,v data, which we will
discuss in more detail shortly.
Sampling Function
Recall the convolution theorem,
which states that the Fourier Transform of a product of two functions is
the convolution of the Fourier Transforms of the individual functions,
and vice versa. If we denote the FT of a function F
as F, then
AB = A * B
(convolution theorem)
A * B = A B
.
where the *
symbol denotes convolution. Application of the convolution theorem
shows that
ID = S(u,v)V(u,v)
= S(u,v) * V(u,v)
which can be interpreted as
saying that the FT of the sampling function, S(u,v),
is convolved with the brightness distribution V(u,v).
We identify the FT of the sampling function, S(u,v),
as the synthesized beam, or
point-spread-function (PSF), or diffraction pattern of the aperture:
S(u,v)
= B(l,m)
(not to be confused with the
baselines, Bλ,proj). We obtain by the synthesized beam by filling in our sampled u,v
points with real part = 1 and imaginary
part = 0. This is exactly what we did
with our exploration of the primary beam pattern for a single dish, if
you will recall. Note that B(l,m)
is also the image we would obtain if we observed a unit point source at
the phase center, since δ(l,m)
= V(u,v) = 1 + 0i, and
ID = B
= S(u,v)V(u,v) = S(u,v)
* δ(l,m) = S(u,v)
Note that this result is very
general, and works just as well for optical systems, where the sampling
function is called the point-spread-function.
Making a Map (Inverting the
Visibilities)
As we noted above,
we invert the sampled visibilities to obtain the dirty image. We
will do an example in class, to demonstrate the relationships shown in
Figure 10. The upper row are the sky plane (l,m) representations
of map, beam, and dirty map. The lower row are the corresponding
u,v plane representations of visibility, sampling function, and sampled
visibility. Panel (f)
represents the actual measurements made by a radio array. Panel (c)
represents the actual image from the array. There are standard image
reconstruction techniques, which we will discuss next time, that essentially
try to predict the missing visibilities in panel (d),
to arrive at the true map (a).

Figure 10: a)
An example (model) sky map. d)
The corresponding visibilities (Fourier Transform of the map).
c) The synthesized
beam, or point-spread-function, of a model antenna array. e)
The sampling function of the
array, whose Fourier Transform
gives the beam in (b). f)
The product of panels (d) and
(e), representing the
sampled visibilities.
These are the actual measurements from the array. c)
The dirty map that results from
the Fourier Transform of
the sampled visibilities. This is the same as the convolution of
the map in (a) and the
synthesized beam in (b).
Sampling Function Issues
Weighting Functions
and Beam Shape
As with any image processing,
it is possible and sometimes desirable to use weighting to control the
point spread function. The synthesized beam may have large positive
or negative sidelobes (the irregularities away from the center of Figure
10b) that we would like to minimize.
There are two important types
of weighting commonly used in radio astronomy, called tapering
and density weighting.
Tapering is used to suppress small-scale variations in the dirty map caused
by incomplete sampling on the longest baselines (the largest u,v
spacings). Often a gaussian taper
T(u,v) = exp[−(u2
+ v2)/σ2]
is used, where σ
is a measure of the width of the taper. Note that the shape of the
beam is improved at the expense of spatial resolution. This is analogous
to smoothing, and is also used routinely in optical image processing.
Other forms of taper can be used--even "negative taper" where the outer
u,v
points are enhanced to improve spatial resolution.
The other important type
of weighting is density weighting, in which the weighting factor is proportional
to the number of u,v measurements
in a given gridded cell. Two common choices are
Dk = 1
Natural weighting
Dk = 1/NS(k)
Uniform weighting
where Dk
is the weight to be applied to cell k,
and NS(k)
is the number of samples falling into cell k.
It is typical for arrays to have a much larger number of short baselines
that long ones. This is especially true of the Nobeyama array, which
has a huge number of baselines of length d, and only a few larger ones:
. . . . . . . . .
. .
. .
|--4d---| |--4d---|
|--4d---|
Lots of 4d spacings
|--------------------23d----------------------|
Only one 23d spacing
This is made worse by the rate
of angular change in the u,v
plane when integrating over some time.
As a rule, uniform gridding
gives the more pleasing result, with the full resolution of the array.
However, when mapping an extended source a natural weighting gives smoother
extended emission by minimizing the negative inner sidelobes. Other
techniques can be used in later image reconstruction to influence the resolution
and sensitivity to extended emission, which we will cover next time.
Gridding
In order to use the FFT
algorithm, the measured u,v
points must be gridded into the 2-d array to be inverted. As it turns
out, the precise way in which this is done can greatly affect the macroscopic
properties of the resulting image. The procedure can be thought of
as a convolution, and we now look at some gridding convolution functions
C(u,v).
-
Pillbox
-
Truncated exponential
-
Truncated sinc function
-
Exponential times truncated
sinc
-
Truncated spheroidal
These are truncated of necessity
because they involve examining a range of FFT cells and seeing which u,v
points lie within the search range--typically 6 or 8 cells. Each
is truncated to
a width of m
cells so that
C(u) = 0
for |u| > mΔu/2.
where Δu is the u,v plane cell
spacing.
-
Pillbox
C(u) = 1 for
|u|
< mΔu/2
0 otherwise
This is equivalent to "nearest
neighbor" if m = 1, and one
simply sums the data in each cell. This is the fastest algorithm,
but suffers the worst aliasing problems. Remember that C*V
= C V, so the image V
is multiplied by C, which
for a pillbox is just a sinc function.
-
Truncated Exponential
C(u) = exp[−(|u|/wΔu)α]
where typically m
= 6, w = 1, and α
= 2 (gaussian). Then C
is also a gaussian and falls off as a gaussian outside the map.
-
Truncated Sinc
C(u) = sinc(u/wΔu)
where typically m
= 6, w = 1. If we use a width
m
= width of the map (expensive in compute time!), then C
is a square wave and falls off sharply, which is the justification for
this functional form.
I will not go through the others,
but one can see that gridding is an important part of inverting the measurements
to get the cleanest possible image. Again, gridding is forced upon
us by use of the FFT. It completely disappears if we use the discrete
Fourier Transform.
Complete Mathematical Representation
Define
V(u,v) = actual visibility function
V ' (u,v) = measured (i.e. noisy)
visibility function
W(u,v) = T(u,v) D(u,v)
= weighting function, including both taper and density weighting
C(u,v) = gridding convolution function
R(u,v) = Resampling function (bed of nails
function, representing pixelization)
R(u,v) = III(u/Δu,v/Δv)
= ΣjΣkδ(j−u/Δu,
k−v/Δv)
The final resampled
visibility function is
VR = R [C
* (WV ' )]
and after FFT we obtain the
"dirty image"
ID = VR
= R * [C (W * V
' )]
The convolution with R
is the step that causes aliasing, so we choose a gridding convolution function
C(u,v)
that minimizes aliasing.
Image Reconstruction
Image Restoration (Deconvolution)
Once we have the dirty image, ID, we need to do more work to obtain a high quality image. There are two main approaches, and both are nonlinear, so are not easy to treat mathematically. The first is called CLEAN, from the term used by its inventor Hogbom (1974, "Aperture Synthesis with a Non-Regular Distribution of Interferometer Baselines," Astronomy & Astrophysics Supplement Series 15, 417.). The second is the Maximum Entropy Method (MEM).
Before detailing these methods, we should ask what range of spatial scales we can expect to recover in an image. The smallest source (hence related to pixel size) is given by Δl = 1/2umax, Δm = 1/2vmax, while the largest source (hence related to the map size) is given by NlΔl = 1/umin, NmΔm = 1/vmin. A rule of thumb for an appropriate map pixel size is Δl = 1/3umax, Δm = 1/3vmax in order to have three pixels per smallest fringe. There may be reasons to specify a larger map, for example to map out to the edge of the primary beam, and there may be other limitations to the field of view, such as due to bandwidth limitations (as in your homework problem) or violation of the flat plane of the sky assumption.
After gridding, our resampled visibility array has some cells populated and other cells empty (those that do not correspond to a u,v point measured with the array). The Fourier Transform inversion is not unique, because these unmeasured points could have any value without violating the data constraints. One particular solution, where all of the missing measurements are set to zero, is called the principle solution, and of course this is the one that corresponds to the dirty image we have been discussing. However, this is not really a reasonable solution -- one would expect a more continuous distribution of visibilities. The goal of image restoration techniques is to find an algorithm that allows us to guess more reasonable values for the unmeasured points. A priori information is the key to choosing "reasonable" values -- for example, we may exclude negative flux values and attempt to maximize some measure of smoothness in the image.
CLEAN Algorithm
- Find the strength and location of brightest point in the image (or some previously defined portion of the image)
- Subtract from the dirty image at this location the dirty beam B multiplied by peak strength and gain factor γ < 1. (Record the position and the subtracted flux.)
- Go to (1) unless any remaining peak is below some user-specified level. What is left are the residuals.
- Convolve the accumulated point source model with an idealized CLEAN beam (i.e. add back components) usually an elliptical gaussian of the same size and shape as the inner part of the dirty beam.
- Add the residuals from step (3) to the CLEAN image.
A number of similar algorithms have been developed, mostly to speed up the operation for certain types of imaging problems, but primarily they all do the same function.
CLEAN boxes
Step (1) can be restricted to smaller areas of the map if there is some reason to believe that the true emission is confined there. A practical example is shown with OVSA data.
Number of Iterations and Loop Gain
The algorithm subtracts some fraction of the source and sidelobes, and runs to some limit (or number of components Ncl). These are "knobs" to tweak that can affect the resulting map (which shows the nonuniqueness of the solution). Using too high a gain tends to make extended, weak emission undetectable and noisy. Basically the brightness distribution is being decomposed into point sources, and the larger the gain the smaller the number of components. Using a number of components that is too high (by specifying too small a gain) means cleaning into the "noise" and wasting computer time. The values of gain and number of components must be chosen on a case by case basis, depending on the source and data quality.
The Special Problem of the Sun as a Source
When mapping the entire disk of the Sun, on which smaller size-scale sources are located, we have an extreme form of extended emission that would take a very long time to decompose into point sources. Thus, the usual CLEAN algorithm is not appropriate and another approach is needed. This is an example of a general approach in which models for the brightness distribution are used.
A good model for the solar disk is a uniform disk of appropriate size (the radius for example, is not the solar optical radius, but a slightly larger (and frequency dependent) radius of order 10" larger). One scales the disk to the appropriate flux level (perhaps as measured with another telescope), then does a Fourier inversion of the model to obtain the expected u,v visibilities sampled with the array. One can then do a straight vector subtraction of the model visibilities, leaving residuals appropriate to a diskless Sun. One can then use normal cleaning techniques on this modified u,v database, and after making a clean map the disk model can be added back in. The best map will result when an accurate disk model is used.
Subtracting in the u,v Plane
As an example, I was once studying a rapidly varying flare star in the presence of a nearby radio-bright galaxy whose flux density was much stronger than the star I was trying to study. The flare star was so weak that it could not even be seen until the sidelobes of the galaxy were cleaned away.
In order to follow the rapid variations I needed a map once per minute or so, but over ~ 12 hours this is a lot of maps to be CLEANed deeply. Worse, slight variations in cleaning could masquerade as stellar variations. What I did was to restrict the cleaning to the area around the galaxy, then used the clean components as a model of the galaxy. I then subtracted the model (the u,v visibilities of the inverse transformed model) from the u,v data, which created a u,v database containing only the star. I could then restrict my CLEAN to a small region of interest and quickly make maps of the variation. This is all possible because of the linear nature of the Fourier Transform. You can add and subtract in either the map plane or the u,v plane.
MEM Algorithm
The term Maximum Entropy comes from the similarity of the functional form of the "objective" function (the quantity to be maximized) to the statistical entropy in statistical mechanics. However, it is not really entropy and the analogy should not be taken too far. The objective function often used involves
H = −Σk Ik ln Ik/Mke Ik = intensity in kth cell of image,
Mk = "default" image, or model
which has two main attributes -- it produces a positive image everywhere, and the image is "maximally uniform " in a sense. It is said that a solution that maximizes this objective function is the solution to missing u,v points that minimizes the amount of added information. The uniformity comes about by forcing a compression in pixel values, consistent with the data constraints. It is the logarithmic term that does this amplitude compression, and sometimes the objective function used involves a shortened form,
H = −Σk ln Ik/Mke, which also works.
- Start with a default map. This could be a flat map (a delta function in u,v space), or it could be the dirty map. This map becomes the model, M, by which the intensity in each pixel k is divided.
- Calculate the entropy by summing the objective function, given above, over the entire map. (In practice, algorithms minimize the "neg-entropy" H' = −H = Σk Ik ln Ik/Mke).
- Calculate the χ2 difference, over the entire map, between the model visibilities V(uk,vk), and the measured u,v data V(uk,vk),
Δ = χ2 = Σk |V(uk,vk) −V(uk,vk)|2 / σ2
where σ2 is a measure of the measurement errors.
- Determine the objective function (the function to be maximized),
ri = λHi− Δi
where λ is a Langrange multiplier that affects the weighting of the entropy
relative to the data, and i is the iteration number. Increasing λ makes the entropy more important and moves the solution away from the data more quickly, which may cause the algorithm to converge more quickly but can also lead to instability and divergence. Making λ smaller is safer, but can lead to a very large number of iterations before convergence.
- To minimize the negative of the objective function, we determine the functional form for the derivative, which we want to bring closer to zero. This functional form provides an indication of whether we need to increase or decrease the model intensity Ik in each pixel in order to bring that pixel's contribution closer to the minimum.
- We make those adjustments, which forms one iteration, and then repeat the entire process. We continue until the value of χ2 reaches an acceptable limit.
The process then, is one of making slight changes to the brightness in each pixel of the model until the model both matches the data (the contribution of Δ in the objective function) and is sufficiently uniform (the contribution of the entropy term H). By changing the intensities in the map, we are putting non-zero values in the unmeasured u,v points in the u,v plane, but we may also be making changes to the measured points. If so, that will make χ2 worse, but perhaps improve the entropy. The process will stop when we have filled in the unmeasured u,v in a manner that is consistent with the measured ones. The hope is that when we are done we will have a map that is fully consistent with the measured values, is everywhere as uniform as possible, and is everywhere positive.
To discuss image reconstruction further, we will use the NRAO Summer School lecture on imaging and deconvolution.