Research Projects on Large Language Model and Natural Language Processing
- Enhancing Controllability and Explainability in Flowchart Understanding with LLMs
- Advancing Creative Problem-Solving in Mathematics with LLMs
- Advancing Logical Reasoning in LLMs with FaultyMath
- Revolutionizing Table Question Answering with Secure and Efficient LLM Solutions
- Data Augmentation for Text Classification with EASE
Enhancing Controllability and Explainability in Flowchart Understanding with LLMs
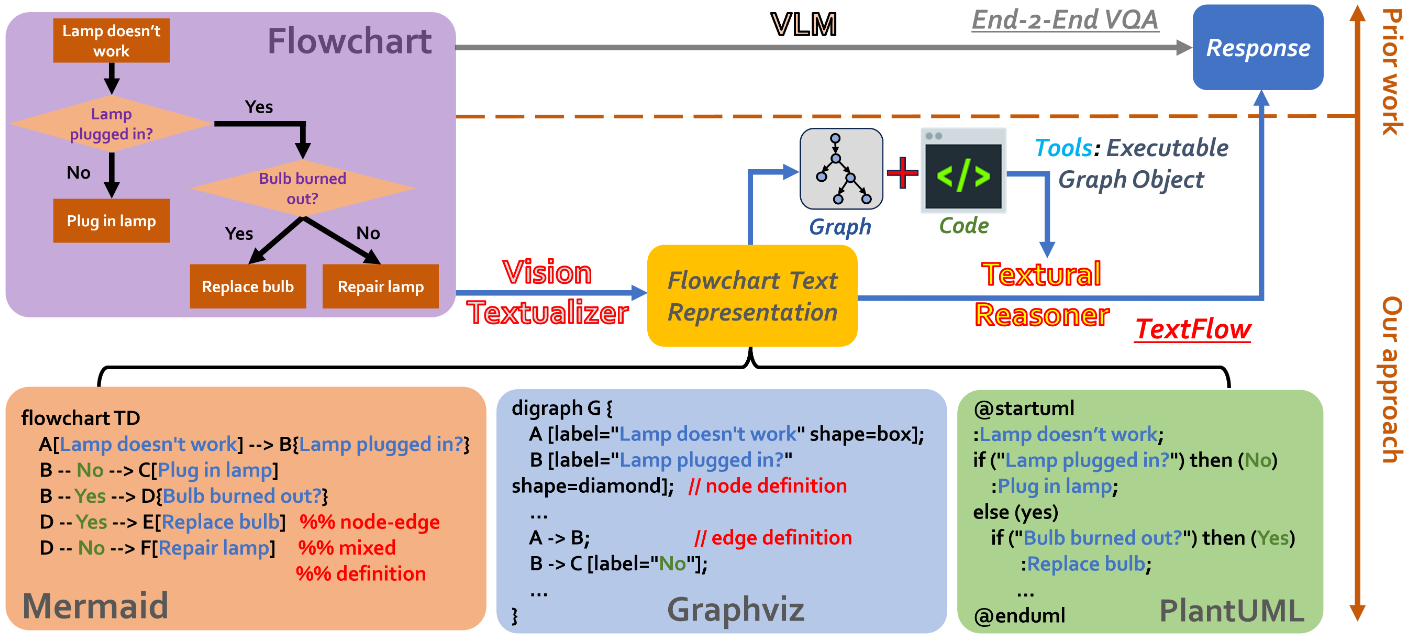
Flowchart understanding, often reliant on vision-language models (VLMs), faces challenges in controllability and explainability. Users have limited ability to influence processing beyond input modification, and errors are difficult to trace due to opaque reasoning processes. To address these issues, we propose a two-stage framework TextFlow: a VLM converts flowchart images into customizable text representations, and an LLM performs reasoning and question-answering on the text. This approach enhances user control, isolates processing errors for improved explainability, and promotes modularity by enabling integration with advanced reasoning tools. The framework’s structured intermediate representations also provide a foundation for generalizing to other multimodal tasks, improving usability and reasoning capabilities.
Advancing Creative Problem-Solving in Mathematics with LLMs
While research on Large Language Models (LLMs) has extensively explored their problem-solving capabilities, their potential for creativity in mathematical reasoning remains underexamined. To bridge this gap, we present CreativeMath, a framework designed to evaluate and enhance LLMs’ innovative reasoning abilities in mathematics. Published at AAAI 2025, CreativeMath introduces a benchmark comprising problems spanning middle school curricula to Olympic-level challenges, systematically assessing the creative problem-solving skills of LLMs. This study sheds light on both the strengths and limitations of LLMs in fostering mathematical creativity and offers a robust benchmark to advance our understanding of their cognitive potential.
Advancing Logical Reasoning in LLMs with FaultyMath
Large Language Models (LLMs) excel at solving standard mathematical problems but often fail to detect logical inconsistencies, raising questions about their ability to reason beyond rote calculation. To address this, we present FaultyMath, a benchmark for evaluating LLMs' capacity to identify and reason about faulty math problems. FaultyMath encompasses diverse categories, including algebra and geometry, with varying difficulty levels and fault types such as contradictions and common-sense violations. It assesses LLMs’ performance in detecting flawed problems, incorporating hints, and providing reasoned explanations. This research underscores the limitations of current LLMs in logical reasoning and establishes a foundation for enhancing their cognitive capabilities, fostering more robust and trustworthy AI systems.

Revolutionizing Table Question Answering with Secure and Efficient LLM Solutions
Table-based question answering with Large Language Models (LLMs) typically requires embedding entire tables into prompts. This approach faces challenges such as context window limitations, high computational costs, and data leakage risks, particularly for large tables. To address these issues, we propose DataFrame QA, a task and framework that generates Pandas queries for information retrieval and analysis on tables. By using only table column names and data types, this approach ensures data privacy, reduces token usage, and enhances efficiency, providing a foundation for secure and scalable LLM-powered tabular data analysis.

Data Augmentation for Text Classification with EASE
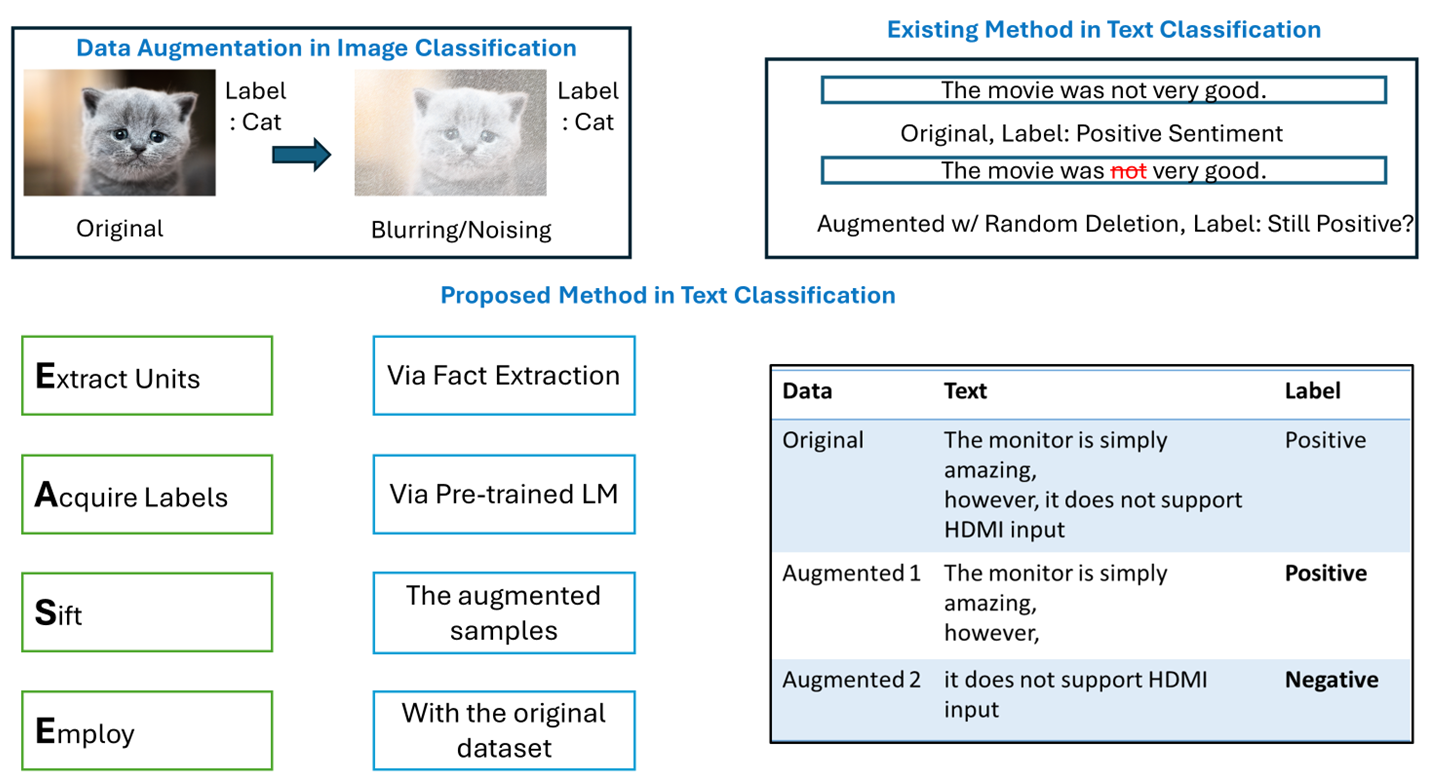
In image classification, efficient data augmentation (DA) is easy with cropping, rotating, blurring etc. It works because a cropped/blurred “cat” is still a “cat”. In other words, the augmented sample does not require additional labeling as in most cases the augmented sample retains the original label. In text classification (TC) existing methods have random insertion, deletion of random words or punctuation, but the semantics change very easily. Therefore, these methods that use the same label for the augmented samples simply inject more noise in many cases. Moreover, acquiring new labels for the augmented sample requires training on the original data first to get a good estimate of the new labels. In this work, we present EASE, a simple but dependable DA technique for TC that has four easy steps: Extract Units, Acquire Labels, Sift and Employ. We extract meaningful units as augmented samples from original data samples and use powerful tools to acquire labels for them before they are sifted and merged. Previous DA techniques, like EDA and AEDA, excel with sequential models but struggle with transformer-based models that heavily rely on token order. EASE, in contrast, performs well with these models, demonstrating stability, speed, and minimal adverse effects. We tested our intuitive method on multiple challenging datasets sensitive to augmentation, and experimental results have indicated the efficacy of DA with EASE.