|
|
Go to COE498 Experiment | 1 | 2 | 3 | 4 | Part List | Lab manuals | ECE Lab home |
|
|
|
Go to COE498 Experiment | 1 | 2 | 3 | 4 | Part List | Lab manuals | ECE Lab home |
|
COE498 Advanced Computer System Design Lab
Chapter 2
Experiment 2
Systolic-Array Implementation of Matrix-By-Matrix Multiplication
2.1 Objective
n x n matrices. For this reason, several parallel algorithms have been developed to solve this problem more efficiently. Here, a simple parallel algorithm is presented for this problem and a "hardwired" (actually, systolic-array) implementation of the algorithm becomes our objective.The multiplication of matrices is a very common operation in engineering and scientific problems. The sequential implementation of this operation is very time consuming for large matrices; the brute-force solution results in computation time O(n3), for
2.2 What You Need
8 8-bit shift registers.
8 LED bar displays and associated SIP resistors (common lead).
2 EPM7064/68s or EPM7096/68s.
Other miscellaneous chips depending on your design.
|
|
|
Figure 2.1: Multiplication of matrices of size 4 4. |
2.3 Introduction
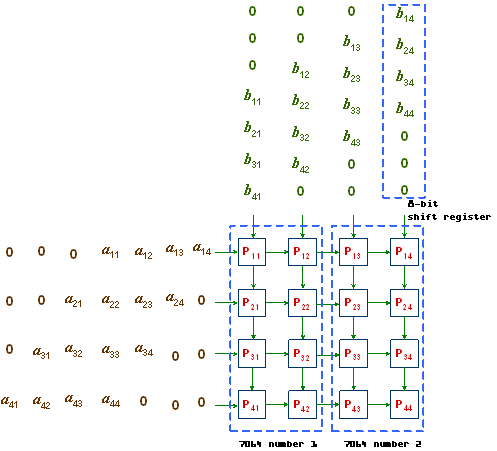
A and B are shifted into the boundary processors in column 1 and row 1, respectively, as shown in Figure 2.2. The leading and trailing 0s in rows and columns are employed so that elements air and brj arrive at processor Pij simultaneously for the operation air ● brj to be performed. cij is initialized to 0 in Pij , for all i, j = 1, 2, 3, 4. At the end, processor Pij will contain cij , for 1 ≤ i, j ≤ 42-dimensional, mesh-connected parallel computers are often used in systolic-array configuration for the multiplication of matrices. For the sake of simplicity, we assume input matrices of size 4 x 4 containing one-bit integer elements. Figure 2.1 shows the operations to be performed. The ● and + represent the integer operations multiplication and addition, respectively.
The two matrices
Whenever a processor
Pij receives two inputs b and a from the north and the west, respectively, it performs the following set of operations, in this order:|
|
|
Figure 2.2: A 4 x 4 mesh (systolic array) of processors for matrix multiplication. |
it calculates
it adds the result to the previous value
it sends
it sends
This algorithm takes time O(n), for n x n matrices.
2.4 Experiment
Implement this parallel algorithm directly in hardware using shift registers and the two Altera chips. Optimize your design with respect to the size of operands. Use LED bar graphs to display the intermediate and final results.
The proper operation of the entire design and each subsection is to be simulated in the Altera simulation software before the chips are programmed and the board is wired. The waveforms from these simulations should be included in the lab report.
|
|
Go to COE498 Experiment | 1 | 2 | 3 | 4 | Part List | Lab manuals | ECE Lab home |
|